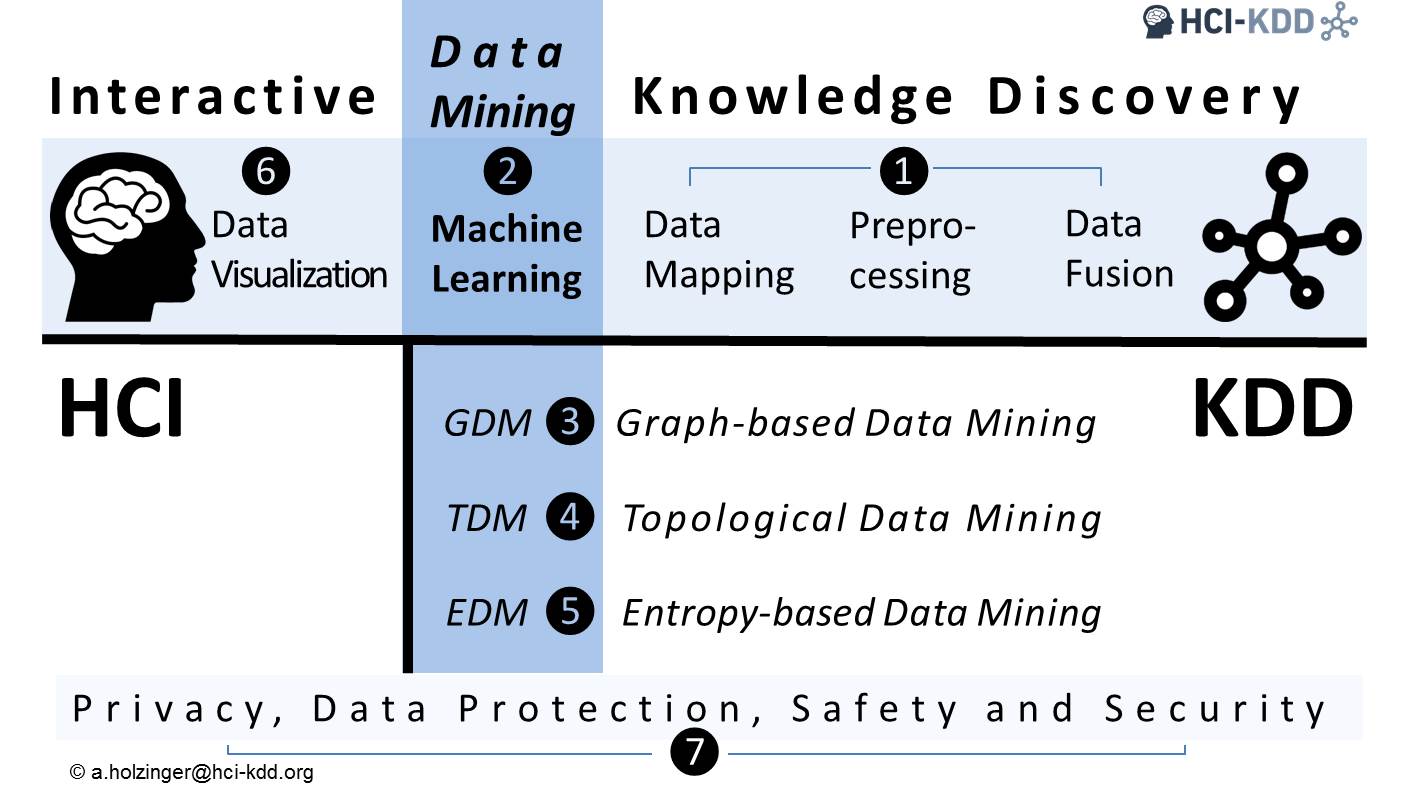
Machine learning is the fastest growing field in computer science, and Health Informatics is amongst the greatest application challenges, providing benefits in improved medical diagnoses, disease analyses, and pharmaceutical development – towards future precision medicine.
Talk announcement: Friday, 12th May, 2017, 10:00, Seminaraum 137, Parterre, Inffeldgasse 16c
Integrated interactomes and pathways in precision medicine
by Igor Jurisica, University of Toronto and Princess Margaret Cancer Center Toronto
Abstract: Fathoming cancer and other complex disease development processes requires systematically integrating diverse types of information, including multiple high-throughput datasets and diverse annotations. This comprehensive and integrative analysis will lead to data-driven precision medicine, and in turn will help us to develop new hypotheses, and answer complex questions such as what factors cause disease; which patients are at high risk; will patients respond to a given treatment; how to rationally select a combination therapy to individual patient, etc.
Thousands of potentially important proteins remain poorly characterized. Computational biology methods, including machine learning, knowledge extraction, data mining and visualization, can help to fill this gap with accurate predictions, making disease modeling more comprehensive. Intertwining computational prediction and modeling with biological experiments will lead to more useful findings faster and more economically.
Short Bio: Igor Jurisica is Tier I Canada Research Chair in Integrative Cancer Informatics, Senior Scientist at Princess Margaret Cancer Centre, Professor at University of Toronto and Visiting Scientist at IBM CAS. He is also an Adjunct Professor at the School of Computing, Pathology and Molecular Medicine at Queen’s University, Computer Science at York University, scientist at the Institute of Neuroimmunology, Slovak Academy of Sciences and an Honorary Professor at Shanghai Jiao Tong University in China. Since 2015, he has also served as Chief Scientist at the Creative Destruction Lab, Rotman School of Management. Igor has published extensively on data mining, visualization and cancer informatics, including multiple papers in Science, Nature, Nature Medicine, Nature Methods, Journal of Clinical Oncology, and received over 9,960 citations since 2012. He has been included in Thomson Reuters 2016, 2015 & 2014 list of Highly Cited Researchers, and The World’s Most Influential Scientific Minds: 2015 & 2014 Reports.
Jurisica Lab, IBM Life Sciences Discovery Center:
Canada Tier I Research Chair: https://www.chairs-chaires.gc.ca/chairholders-titulaires/profile-eng.aspx?profileId=2347
On Nutrigenomics [1]: https://www.uhn.ca/corporate/News/Pages/Igor_Jurisica_talks_nutrigenomics.aspx
[1] Nutrigenomics tries to define the causality or relationship between specific nutrients and specific nutrient regimes (diets) on human health. The underlying idea is in personalized nutrition based on the *omics background, which may help to foster personal dietrary recommendations. Ultimately, nutrigenomics will allow effective dietary-intervention strategies to recover normal homeostasis and to prevent diet-related diseases, see: Muller, M. & Kersten, S. 2003. Nutrigenomics: goals and strategies. Nature Reviews Genetics, 4, (4), 315-322.