
This site uses cookies. By continuing to browse the site, you are agreeing to our use of cookies.
Accept all cookies and servicesDo not acceptLearn moreWe may request cookies to be set on your device. We use cookies to let us know when you visit our websites, how you interact with us, to enrich your user experience, and to customize your relationship with our website.
Click on the different category headings to find out more. You can also change some of your preferences. Note that blocking some types of cookies may impact your experience on our websites and the services we are able to offer.
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
These cookies collect information that is used either in aggregate form to help us understand how our website is being used or how effective our marketing campaigns are, or to help us customize our website and application for you in order to enhance your experience.
If you do not want that we track your visit to our site you can disable tracking in your browser here:
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and Menus of our site. Changes will take effect once you reload the page.
Google Webfont Settings:
Google Map Settings:
Google reCaptcha Settings:
Vimeo and Youtube video embeds:
The following cookies are also needed - You can choose if you want to allow them:
You can read about our cookies and privacy settings in detail on our Privacy Policy Page.
Legal Information – Impressum
“Machine Learning for Health Informatics” Lecture Notes in Artificial Intelligence 9605 > 40,626 downloads 2017
/in HCI-KDD Events, Science News/by Andreas HolzingerSince its online publication on December 10, 2016 the Volume edited by Andreas Holzinger “Machine Learning for Health Informatics” Springer Lecture Notes in Artificial Intelligence LNAI Volume 9605, has been downloaded 54,960 times as of today (May, 11, 2018, 20:00 CEST) and 44,988 with status as of April 2018 according to the official Springer Bookmetrix book performance report – a record; and alone in the year 2017 40,626 downloads, which is 10 times higher than a typical volume of the series of Lecture Notes in Artificial Intelligence by Springer/Nature. A cordial thank you for my international colleagues for this huge acceptance!
https://www.springer.com/978-3-319-50478-0
https://www.springer.com/gp/book/9783319504773
A popular passage from the book:
https://books.google.com/talktobooks/query?q=What%E2%80%99s%20the%20difference%20between%20Machine%20Learning%20and%20deep%20learning%3F
Update on 15th September 2018: 63k downloads
NEW: The Travelling Snakesman v 1.1 – 18.4.2018 released
/in General/by Andreas HolzingerEnjoy the new version of our travelling snakesman game:
https://human-centered.ai/gamification-interactive-machine-learning/
Please follow the instructions given. By playing this game you help to proof the following hypothesis:
“A human-in-the-loop enhances the performance of an automatic algorithm”
AI will change Radiology – NOT replace Radiologists
/in Science News/by Andreas Holzinger[1] https://hbr.org/2018/03/ai-will-change-radiology-but-it-wont-replace-radiologists
Human-in-the-loop AI
/in General/by Andreas HolzingerHuman-in-the-Loop-AI
This is really very interesting. In the recent April, 5, 2018, TWiML & AI (This Week in Machine Learning and Artificial Intelligence) podcast, Robert MUNRO (a graduate from Stanford University, who is an recognized expert in combining human and machine intelligence) reports on the newly branded Figure Eight [1] company, formerly known as CrowdFlower. Their Human-in-the-Loop AI platform supports data science & machine learning teams working on various topics, including autonomous vehicles, consumer product identification, natural language processing, search relevance, intelligent chatbots, and more. Most recently on disaster response and epidemiology. This is a further proof on the enormous importance and potential usefulness of the human-in-the-loop interactive machine Leanring (iML) approach! Listen to this awesome discussion led excellently by Sam CHARRINGTON:
https://twimlai.com/twiml-talk-125-human-loop-ai-emergency-response-robert-munro/
This discussion fits well to the previous discussion with Jeff DEAN (head of the Google Brain team) – who emphasized the importance of health and the limits of automatic approaches including deep learning. Enjoy to listen directly at:
https://twimlai.com/twiml-talk-124-systems-software-machine-learning-scale-jeff-dean/
[1] https://www.figure-eight.com/resources/human-in-the-loop
A good proof of the importance of the HCI-KDD approach, worth: 2,1 Billion USD !
/in General, Science News/by Andreas HolzingerOur strategic aim is to find solutions for data intensive problems by the combination of two areas, which bring ideal pre-conditions towards understanding intelligence and to bring business value in AI: Human-Computer Interaction (HCI) and Knowledge Discovery (KDD). HCI deals with questions of human intelligence, whereas KDD deals with questions of artificial intelligence, in particular with the development of scalable algorithms for finding previously unknown relationships in data, thus centers on automatic computational methods. A proverb attributed perhaps incorrectly to Albert Einstein illustrates this perfectly: “Computers are incredibly fast, accurate, but stupid. Humans are incredibly slow, inaccurate, but brilliant. Together they may be powerful beyond imagination” [1].
An article published on February, 18, 2018 by David Shaywitz [2] from Forbes reports on the recent purchase of the oncolology data company Flatiron Health for the enormous sum of 2,1 Billion USD (remember: Deep Mind was purchased by Google for a mere 400 million GBP 😉
This supports a few hypotheses which I try to convince my students all the time (but they won’t believe me unless Google is doing it 😉
a) those who can turn raw health data into insights and understandable knowledge can produce value
b) data – and particularly big data – is useless for the decision maker, what they need is reliable, valuable and trustworthy information
c) for the complexity of sensemaking from health data we (still) need a human-in-the-loop: Humans (still) exceed machine performance in understanding the context and explaining the underlying explanatory factors of the data
d) consequently this is a good example for the business value of our HCI-KDD approach: Let the computer find in arbitrarily high-dimensional spaces what no human is able to do – but let the human do what no computer is able to do: BOTH working together are powerful beyond imagination!
Flatiron Health [3] is a company which is specialized on health data curation, supported by technology of course, but mostly done manually by human experts in the Mechanical Turk style. Remark: The name mechanical turk has historic origins as it was inspired by an automatic 18th-century chess-playing machine by Wolfgang von Kempelen, that beats e.g. Benjamin Franklin in chess playing – and was acclaimed as “AI”. However, ti was later revealed that it was neither a machine nor an automatic device – in fact it was a human chess master hidden in a secret space under the chessboard and controlling the movements of an humanoid dummy. Similarly, services which help to solve problems via human intelligence are called “Mechanical Turk online services”.
[1] Holzinger, A. 2013. Human–Computer Interaction and Knowledge Discovery (HCI-KDD): What is the benefit of bringing those two fields to work together? In: Cuzzocrea, Alfredo, Kittl, Christian, Simos, Dimitris E., Weippl, Edgar & Xu, Lida (eds.) Multidisciplinary Research and Practice for Information Systems, Springer Lecture Notes in Computer Science LNCS 8127. Heidelberg, Berlin, New York: Springer, pp. 319-328, doi:10.1007/978-3-642-40511-2_22
[2] https://www.forbes.com/sites/davidshaywitz/2018/02/18/the-deeply-human-core-of-roches-2-1b-tech-acquisition-and-why-they-did-it/#6242fdbc29c2
[3] https://flatiron.com
On-Device Machine Intelligence
/in General, Science News/by Andreas HolzingerOne very interesting approach of federated machine learning is presented by Sujith Ravi from Google: Machine learning models (e.g. CNN) are sucessfully used for the design of intelligent systems capable of visual recognition, speech and language understanding. Most of these are running on a cloud – which is often inpredictable where it is physically running. A huge problem so far is that typical machine learning models are awkward to use on mobile devices due to both computational and memory constraints. While these devices could make use of models running on high-performance data centers with CPUs or GPUs, this is not feasible for many applications and scenarios where inference needs to be performed directly “on” device. This requires re-thinking existing machine learning algorithms and coming up with new models that are directly optimized for on-device machine intelligence rather than doing post-hoc model compression. Sujith Ravi is introducing a novel “projection-based” machine learning system for training compact neural networks. The approach uses a joint optimization framework to simultaneously train a “full” deep network and a lightweight “projection” network. Unlike the full deep network, the projection network uses random projection operations that are efficient to compute and operates in bit space yielding a low memory footprint. The system is trained end-to-end using backpropagation. Ravi shows that the approach is flexible and easily extensible to other machine learning paradigms, for example, they can learn graph-based projection models using label propagation. The trained “projection” models are then directly used for inference, please watch the origial video on:
Prefetching – Predicting what will be most likely needed next
/in Science News/by Andreas HolzingerA very interesting paper has just been published about prefetching, which is a nice machine learning solution: predicting which information will be most likely useful next and consequently can be prepared in advance:
Milad Hashemi, Kevin Swersky, Jamie A Smith, Grant Ayers, Heiner Litz, Jichuan Chang, Christos Kozyrakis & Parthasarathy Ranganathan 2018. Learning Memory Access Patterns. arXiv preprint arXiv:1803.02329.
Prefetching is the process of predicting future memory accesses that will miss in the on-chip cache and access memory based on past history. Each of these memory addresses are generated by a memory instruction (a load/store). Memory instructions are a subset of all instructions that interact with
the addressable memory of the computer system.
There is a nice article in the MIT Technology Review by Will Knight on March, 8, 2018 on the similarities on how human improve their behaviour with age – a very nice read:
https://www.technologyreview.com/s/610453/your-next-computer-could-improve-with-age/?set=
Python in Machine Learning still Nr. 1 and increasing
/in General/by Andreas HolzingerThere is of course no such thing like a ‘best language for machine learning’ – but as a matter of fact Python is still Nr. 1 and increasing:
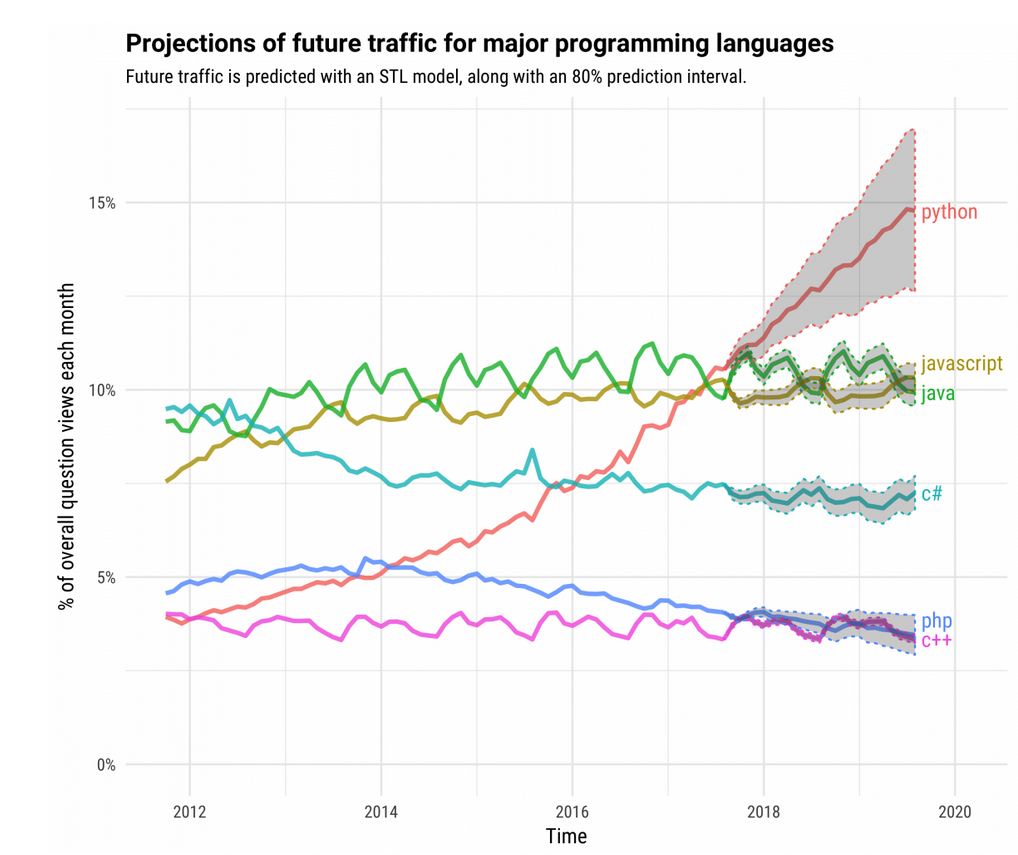 Image Source: https://stackoverflow.blog/2017/09/06/incredible-growth-python/
Image Source: https://stackoverflow.blog/2017/09/06/incredible-growth-python/
We use in all our courses Python due to the fact that it is an “industrial standard” and widely available. I would love e.g. Julia, which is much faster, but it remains rather academic and needs a lot of additional effort. It is not astonishing that Python is worldwide the most popular tool for machine learning and artificial intelligence as there are deep learning frameworks available, including Tensor Flow, Pandas, NumPy, PyBrain, Scikit, SimpleAI, EasyAI, etc. etc.
Consequently, in our courses we teach Python, have a look at:
Marcus D. Bloice & Andreas Holzinger 2016. A Tutorial on Machine Learning and Data Science Tools with Python. In: Holzinger, Andreas (ed.) Machine Learning for Health Informatics, Lecture Notes in Artificial Intelligence LNAI 9605. Heidelberg: Springer, pp. 437-483, doi:10.1007/978-3-319-50478-0_22. [link to paper]
iML with the human-in-the-loop mentioned among 10 coolest applications of machine learning
/in General, Science News/by Andreas HolzingerWithin the “Two Minute Papers” series, Karol Károly Zsolnai-Fehér from the Institute of Computer Graphics and Algorithms at the Vienna University of Technology mentions among “10 even cooler Deep Learning Applications” our human-in-the-loop paper:
Seid Muhie Yimam, Chris Biemann, Ljiljana Majnaric, Šefket Šabanović & Andreas Holzinger 2016. An adaptive annotation approach for biomedical entity and relation recognition. Springer/Nature: Brain Informatics, 3, (3), 157-168, doi:10.1007/s40708-016-0036-4
Watch the video here (iML is mentinoned from approx. 1:20):
Here the list of all 10 papers discussed within this 2-minutes-video
1. Geolocation – https://arxiv.org/abs/1602.05314
2. Super-resolution – https://arxiv.org/pdf/1511.04491v1.pdf
3. Neural Network visualizer – https://experiments.mostafa.io/public/…
4. Recurrent neural network for sentence completion:
5. Human-in-the-loop and Doctor-in-the-loop: https://link.springer.com/article/10.1007/s40708-016-0036-4
6. Emoji suggestions for images – https://emojini.curalate.com/
7. MNIST handwritten numbers in HD – https://blog.otoro.net/2016/04/01/generating-large-images-from-latent-vectors
8. Deep Learning solution to the Netflix prize – https://karthkk.wordpress.com/2016/03/22/deep-learning-solution-for-netflix-prize/
9. Curating works of art –
10. More robust neural networks against adversarial examples – https://cs231n.stanford.edu/reports201…
The Keras library: https://keras.io/
A) The basic principle of the iML human-in-the-loop approach:
Andreas Holzinger 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Brain Informatics, 3, (2), 119-131, doi:10.1007/s40708-016-0042-6
B) The entry in the GI Lexikon:
https://gi.de/informatiklexikon/interactive-machine-learning-iml
C) The experimental proof-of-concept:
Andreas Holzinger, Markus Plass, Katharina Holzinger, Gloria Cerasela Crisan, Camelia-M. Pintea & Vasile Palade 2017. A glass-box interactive machine learning approach for solving NP-hard problems with the human-in-the-loop. arXiv:1708.01104.
D) Outline and Survey of application possibilities:
Andreas Holzinger, Chris Biemann, Constantinos S. Pattichis & Douglas B. Kell 2017. What do we need to build explainable AI systems for the medical domain? arXiv:1712.09923.
Andreas Holzinger, Bernd Malle, Peter Kieseberg, Peter M. Roth, Heimo Müller, Robert Reihs & Kurt Zatloukal 2017. Towards the Augmented Pathologist: Challenges of Explainable-AI in Digital Pathology. arXiv:1712.06657.
NIPS-2017 Best paper “Explainability was one of the major reasons the paper was given the award”
/in General/by Andreas HolzingerCongratulations to Arthur GRETTON from the Gatsby Computational Neuroscience Unit at the University College London an his team. Their paper titled “A Linear-Time Kernel Goodness-of-Fit Test” authored by Wittawat JITKRITTUM, Wenkai XU, Zoltan SZABO, Kenji FUKUMIZU and Arthur GRETTON won the prestigous NIPS 2017 best paper award. In the interview by Sam Charringtion from TWiML&AI, the authors of the NIPS 2017 best paper said at 14:10 in the following video that ” … explainability was one of the reasons that the paper was given the award …”, listen here:
Here is the original talk:
https://papers.nips.cc/paper/6630-a-linear-time-kernel-goodness-of-fit-test
In their paper the authors propose a novel adaptive test of goodness-of-fit, with computational cost linear in the number of samples. They learn the test features, which best indicates the differences between the observed samples and a reference model, by means of minimizing the false negative rate. These features are constructed via the Stein’s method, i.e. that it is not necessary to compute the normalising constant of the model. They further analyse the asymptotic Bahadur efficiency of the new test, and prove that under a mean-shift alternative, the test always has greater relative efficiency than a previous linear-time kernel test, regardless of the choice of parameters for that particular test. In experiments, the performance of their method exceeds that of the earlier linear-time test, and matches or exceeds the power of a quadratic-time kernel test. In high dimensions and where model structure may be exploited, this new goodness of fit test performs far better than a quadratic-time two-sample test based on the Maximum Mean Discrepancy, with samples drawn from the model.
The original paper can be downloaded via the NIPS pages:
https://nips.cc/Conferences/2017/Schedule?showEvent=8823
The paper is also available at arXiv:
Jitkrittum, W., Xu, W., Szabo, Z., Fukumizu, K. & Gretton, A. 2017. A Linear-Time Kernel Goodness-of-Fit Test. arXiv preprint arXiv:1705.07673.