

Welcome to the class of 2021
Current as of 16.06.2021, 10:00 CEST (UTC+2), 07:00 MDT (UTC-6), 00:00 AEDT (UTC+11)
Students will find all course information here on this course homepage – please check regularly.
Course started on Monday, March, 8, 2021, 18:00 CET = 10:00 MST = 04:00 AEST
Those students who wish to participate in this course must be present online on that day and time.
(When planning meetings please mind the time shift between Edmonton, Graz, and Sydney,
and note that there will be different daylight savings times taking into effect)
NOTE: The course will be finished individually with your tutor, since some of the students asked for
a longer duration to complete their tasks, the rule is valid: You get your grading when submitting your work to the tutors,
there is no deadline.
LV-Team of 2021 of the HCAI-Lab:
Andreas HOLZINGER, Anna SARANTI, Miroslav HUDEC, Marcus BLOICE, Lukas GRASSAUER, Claire and Fleur JEANQUARTIER
This year we welcome distinguished guest professors who will also help in supervision of the Miniprojects:
Matthew E. TAYLOR, Intelligent Robot Learning Lab (IRL Lab) at the University of Alberta, Edmonton, Canada
Andre M. CARRINGTON, Ottawa Hospital Research Institute (OHRI), Ottawa, Canada
Jianlong ZHOU, Human-Centered AI Lab at the University of Technology Sydney, Australia
Natalia DIAZ-RODRIGUEZ, AI-Lab, ENSTA (École Nationale Supérieure de Techniques Avancées), INRIA, Paris, France
GENERAL INFORMATION:
AK HCI, 21S, 706.046, Summer term 2021, 4,5 ECTS, 3 VU, Selective subject for 921 Computer Science (C4 Games Engineering – Human-Computer Interaction, F3 Interactive and Visual Information Systems), for 924 Software Engineering and Management, and for Doctoral School Computer Science, i.e. 786 Doctoral Programme in Technical Sciences, and 791 Doctoral Programme in Natural Sciences.
COURSE DESCRIPTION:
CONTENT: In this research-based teachig (RBT) course you will work on specific Mini Projects in groups of 1 to 3 students and – guided by a tutor – learn to experiment and apply scientific methods and their practical implementation in experimental software engineeering. Software Engineering is seen as dynamic, interactive and cooperative process which facilitate an optimal mixture of standardization and tailor-made solutions. General motto of this course: Science is to test crazy ideas, Engineering is to put these ideas into Business.
PREVIOUS KNOWLEDGE EXPECTED: General interest in the interface between human intelligence and artificial intelligence (AI). Special interest in human-centered AI (HCAI) and “explainable AI” (xAI) to enable human experts to retrace machine decisions, thus making it human understandable why an algorithm produced a certain result. One goal of the course is to raise awareness for ethically responsible AI and transparent, interpretable and verifiable machine learning.
ASSESSESMENT: Individual as well as Group work will be assessed on both process and product, and each student is then asked for her/his contribution to the outcome, we follow CMU, see: https://www.cmu.edu/teaching/assessment/assesslearning/groupWork.html
08.o3.2021, Monday, 18:00 pm CET, 10:00 am MST, 04:00 am AEST
- Part 1) Welcome and overview to the principles of this course by the team of the HCAI-Lab
- Part 2) Top-level presentation of the central topics of the class of 2021 (find title, abstract and short bios of the guest professors below)
- Part 3) Students speak: short and concise 1-minute self-introduction (elevator speech style) of each student answering three questions:
- 1) Background and status of study (past – present – future)
- 2) Topical interests and expectations to this course
- 3) Level of programming experience
- Part 4) Question-answer round
- Part 5) Closing
- As the course progresses the goal is to match each student to the optimal Mini Project according to his or her interests and abilities.
- Mini Project -> Group (Note: A group can consist of 1, 2, or 3 students)
- In the list below you find the top-level descriptions of the Mini Projects, the details are in the TeachCenter and/or will be individually set between the group and the group tutor.
Matthew E. TAYLOR, University of Alberta, Edmonton, Canada (MST time zone)
Title: Explainability in Reinforcement Learning
Bio: Matt has been working on reinforcement learning and multiagent systems since 2003. After his PhD in 2008, he worked as a postdoc, a professor at a small college, a professor at a university, and then hopped into industry for a few years. He currently directs the Intelligent Robot Learning Lab (irll.ca) at the University of Alberta and is a Fellow-in-Residence in Amii, the Alberta Machine Intelligence Institute. His current fundamental research interests are in reinforcement learning, human-in-the-loop AI, multi-agent systems, and robotics. His applied research interests revolve around getting cutting edge machine learning and AI out of academic labs and into the hands of companies whose names don’t begin with the letters FAANG.
Abstract: Reinforcement learning (RL) has become increasingly popular, from video games to robot control to stock trading. However, in order to get buy-in from users and decision makers, it’s often very important to be able to explain how an agent acts. If you just say “it’s a black box, trust me!” you may not get very far. While there are many recently-introduced methods to help improve explainability, there are many remaining open questions. We will discuss a few existing methods, as well as potential low-hanging fruit for explainability in RL, as well as what it means for explainability to actually be useful for expert or non-expert users.
Natalia Diaz RODRIGUEZ, Institut Polytechnique Paris, ENSTA (École Nationale Supérieure de Techniques Avancées), INRIA, Paris, France (CET time zone)
Title: Combining Symbolic AI with statistical machine learning
Bio: Natalia is Professor of Artificial Intelligence at the Autonomous Systems and Robotics Lab at ENSTA ParisTech. She also belongs to the INRIA Flowers team on developmental robotics. Her research interests include deep, reinforcement and unsupervised learning, (state) representation learning, explainable AI and AI for social good. She is working on open-ended learning and continual/lifelong learning for applications in computer vision and robotics. Her background is on knowledge engineering (semantic web, ontologies and knowledge graphs) and is interested in neural-symbolic approaches to practical applications of future AI.
Abstract: The latest Deep Learning (DL) models for detection, classification and image captioning have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience such as end-users or domain experts. In contrast, symbolic AI systems that convert concepts into rules or symbols –such as knowledge graphs– are easier to explain. However, they present lower generalisation and scaling capabilities. One way to address this performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. This project will study models and techniques including explainable Neural Symbolic learning and reasoning and techniques to make deep learning explainable to different audiences, including domain experts, causality based explanations and methods designed to learn both symbolic and deep representation.
Andre CARRINGTON, Ottawa Hospital Research Institute (OHRI), Ottawa, Canada (EST Time Zone – same as New York)
Title: Towards “Elements of AI”
Bio: André received his Ph.D in systems design engineering at the Vision and Image Processing lab at the University of Waterloo in 2018 with a dissertation and work on artificial intelligence (AI) applied to health care. He also has an M.Math (computer science) and B.A.Sc from the same. Prior to graduate school, André had health informatics experience at Canada Health Infoway and Alberta Health and Wellness. He is joining the medical imaging department as an associate scientist from his current position as an AI postdoctoral fellow in clinical epidemiology. André’s research interests in AI for medical imaging include: explainable AI, the quality of medical image datasets for robust learning, performance measures for optimal and robust decision making, and the opportunities and implications to medical imaging from recent advances in AI.
Abstract: In many health care applications and other high-assurance domains we seek optimal and robust tools to reduce errors not just overall, but also for each individual and subgroup. We lack understanding at all points in the machine learning process from data to algorithms to how we use an algorithm’s output in decision-making or knowledge integration. Ideally, if there were an atomic/quantum model and periodic table for AI then its impact would be substantial and widespread. The more we understand AI, the more we can improve it. To that end, we have the opportunity to tinker, to challenge assumptions and/or consider elemental hypotheses in hopes of contributing to the “Elements of AI”.
Jianlong ZHOU, Human-Centered AI Lab, University of Technology (UTS), Sydney, Australia (AEST timezone)
Title: Explanation to machine learning and perception of fairness
Bio: Dr. Zhou’s research interests include ethics of AI, AI explanation, AI fairness, interactive behaviour analytics, human-computer interaction, and visual analytics. He has extensive experiences in data driven multimodal human behaviour understanding in AI-informed decision making. He leads interdisciplinary research on applying human behaviour analytics in trustworthy and transparent machine learning. He also works with industries in advanced data analytics for transforming data into actionable operations, particularly by incorporating human user aspects into machine learning to translate machine learning into impacts in real world applications..
Abstract: Machine learning (ML) is a black box for domain users, where users input data to the ML model and get predictions and/or diagrams as the output, but users do not know how the input data were processed to get the output, which may affect user trust in ML-informed decision making. Therefore, ML explanations are proposed to interpret why a prediction was made in ML. Furthermore, fairness in ML is the absence of any prejudice or favoritism toward an individual or a group based on their inherent or acquired characteristics. An unfair algorithm is one whose decisions are skewed toward a particular group of people. We will discuss the relations between ML explanations and perception of fairness in ML-informed decision making through user experiment studies.
Below you will find a selection of 20 Mini Projects (Mini Project 00 to Mini Project 19) in random order in top-level description. Details, schedules and deliverables, as well as individual means of communication (e.g. email contacts, Slack, Discord, or any other) will be arranged directly with the respective group tutors. We want to match the ideally suited students (knowledge, expertise, interest) to the most suitable Mini Project. The matchmaking will be made via the TeachCenter. Please proceed to the TeachCenter and enroll to the respective group – first come first serve principle.
Mini Project 00 + 01: Understanding Reinforcement Learning Agents (for Games *)
Goal: Several ideas (see tasks below) are to be evaluated and this Mini Project should lead to a clear go/no-go decision as to whether the particular idea being investigated is worth exploring further or should be abandoned. *) Games are an excellent playground for the study of explainable AI.
Description: Reinforcement learning (RL) is a popular machine learning technique useful for many applications ranging from smart health to smart farming. Unfortunately, it is often a “black box” [1], which makes understanding, debugging, deployment, trust, adoption and the quest for causality [2] all more difficult. While there have been many initial approaches to explainability for RL [3], there is to date no dominant method. Many papers take a “look, this makes sense!” approach, rather than actually testing and evaluating whether and to what extend the explanations actually allow a human to do something with the information (e.g., select which agent is better, understand the agent’s reward function, predict how the agent will act in a novel situation, etc.). Such experiments may take place in game environments, but other RL environments can be considered. Minimal understanding of reinforcement learning will be needed. A machine learning background (or willingness to quickly learn) will be useful for some tasks and critical for others.
Tasks: (1) Compare different existing explainability methods for RL to better understand if/where they work. This could directly build on a current MSc student’s work (who will defend in the next few months). (2) Use an object-based RL method for explainability. This would let us consider things like “Pac-man is moving left because of the yellow ghost” or “The spaceship is moving right because of this alien.” This would be an extension of existing RL-learning methods, based on a semi-novel CNN method. (3): Investigate interpertable RL. While there has been some work on RL methods that can be directly understandable by humans, there are many opportunities for future improvement. This project would first investigate different existing methods, looking at how understandable current methods are and how performance suffers relative to non-interpretable methods. The project would then try to introduce 1+ methods that improve on interpertable RL methods, with significant help from Matt. (4) Programmatic policies use human-readable, code-like instructions to build policies. There are multiple ways of learning such policies directly, or converting neural-network policies to human-readable code. This project would build upon a MSc student’s work in this area (hopefully defending in Fall 2021), looking at how to best learn such a policy that’s human understandable, how to make the policy perform as well as possible in the task, and evaluate how well different users could understand the policy. (5): User-specific explanations. Different users have different levels of sophistication. It would be ideal if explanations could change/adapt/interact, depending on the given user. This project will look at 2+ existing explainability methods for RL and see how the explanations can be adapted. In the simplest case, this could be investigating the tradeoff between accuracy and brevity. However, we anticipate multiple approaches to understanding how to adapt explanations per-user could be investigated.
Tutors: Matt TAYLOR & Course Team
References:
[1] Douglas, N., Yim, D., Kartal, B., Hernandez-Leal, P., Maurer, F. & Taylor, M. E. Towers of saliency: A reinforcement learning visualization using immersive environments. Proceedings of the 2019 ACM International Conference on Interactive Surfaces and Spaces, 2019. 339-342, https://doi.org/10.1145/3343055.3360747
[2] Madumal, P., Miller, T., Sonenberg, L. & Vetere, F. 2019. Explainable Reinforcement Learning Through a Causal Lens. https://arxiv.org/abs/1905.10958
[3] Heuillet, A., Couthouis, F. & Díaz-Rodríguez, N. 2020. Explainability in deep reinforcement learning. Knowledge-Based Systems, 214, 106685, https://doi.org/10.1016/j.knosys.2020.106685
Assigned to: GROUP GHI and KSW
(Here two groups will be assigned, therefore it will be Mini Project 00 and Mini Project 01)
Mini Project 02: Online System Causability Scale (SCS)
Goal: Design, Develop, Implement and evaluate an online tool for the system causability scale (SCS) [1] and apply it in an online study.
Description: Prediction models are useful if we can understand hence trust their results, and if we are able to integrate the knowledge that they provide as estimates, recommendations or conclusions about a current or future state or choice. Understanding a prediction model’s behaviour also yields opportunities to improve the model.
Tasks: Choose an online prediction tool [2], [3] or your own prediction tool, that a sample of your peers can understand, access and use. Develop an online tool to obtain the answers to the system causability scale [1] and output the result – with a comment box for each component in the scale to capture: (a) any comments about difficulty interpreting the component; and (b) any observations the evaluator has about how the system could be enhanced to achieve a better score. Enroll 10+ users who will use the prediction tool and evaluate their experience using the system causability scale. Write a report about the study along with conclusions and recommendations about the tool and the scale.
Tutors: André CARRINGTON & Course Team
References:
[1] Holzinger, A., Carrington, A. & Mueller, H. 2020. Measuring the Quality of Explanations: The System Causability Scale (SCS). Comparing Human and Machine Explanations. KI – Künstliche Intelligenz (German Journal of Artificial intelligence), 34, (2), 193-198, doi:10.1007/s13218-020-00636-z
[2] https://www.projectbiglife.ca/life-expectancy-home
[3] https://www.pbrc.edu/research-and-faculty/calculators/weight-loss-predictor
Assigned to: GROUP RU
Mini Project 03: Tinkering with “Elements of AI” for optimal, robust & explainable performance
Goal: Propose and examine elements of data and AI algorithms that can be changed in isolation, and ideally incrementally, contribute toward understanding learning in AI.
Description: In supervised learning we seek optimal and robust performance yet we do not fully understand the nature of patterns and behaviours in data, machine learning, decision-making and knowledge integration. This motivates explainable AI because we can effectively and efficiently improve AI if we understand it. By analogy, what is the atomic/quantum model and periodic table for AI? By examining underlying assumptions and elemental components of learning we may be able to discover and describe the “Elements of AI”. For example, how do machine learning systems evolve in training [1]? How can we tinker with data to understand and measure how a system learns [2]? What make a data set difficult [3] relative to an algorithm’s capacity [4]? Most of all: What makes a data set robust?
Tasks: Choose a machine learning method to examine, e.g., neural networks or support vector machines. Generate elemental data sets that can be incrementally changed to observe and quantify the effect on learning. Use only a few features and simple bimodal then trimodal multivariate distributions. With a benchmark data set, investigate the effect on machine learning performance caused by pre-processing data with different unsupervised transformations that can ideally be changed incrementally. For example, kernel principal components analysis reduces to principal components analysis for a linear kernel. Increments could be achieved with different degrees of a polynomial kernel or a power kernel. Identify confounding factors.
Tutors: André CARRINGTON, Andreas HOLZINGER & Team
References:
[1] Raudys Š. Evolution and generalization of a single neurone. III. Primitive, regularized, standard, robust and minimax regressions. Neural networks. 2000 Jun 1;13(4-5):507-23.
[2] Christopher Olah. Neural Networks, Manifolds, and Topology. 2014 April. https://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
[3] Smith MR, Martinez T, Giraud-Carrier C. An instance level analysis of data complexity. Machine learning. 2014 May;95(2):225-56.
[4] Vapnik V. The nature of statistical learning theory. Springer science & business media; 2013 Jun 29.
Assigned to: GROUP NN
Mini Project 04: KANDINSKYPatterns Explanation Game
Goal: Develop a graphical application front end which supports the gamification of explaining KANDINSKY Figures and KANDINSKYPatterns.
Description: To understand human explanation patterns, one goal is to gather natural language explanations of KANDINSKYPatterns [1], [2].
However, this is a difficult challenge so the goal is to simplify the problem by making use of a gamification approach. This can be achieved e.g. when explanations are reduced from natural language to actions in a discrete action space.
Tasks: To design, develop, test and evaluate an graphical application which supports selected requirements, for example:
– Highlighting a region in a KANDINSKY Figure.
– Grouping multiple objects in a KANDINSKY Figure.
– Adding an object to a KANDINSKY Figure and reevaluating if it is in the pattern or not.
– Noticing geometric configurations (all objects are on a line etc.)
Tutors: Lukas GRASSAUER, Andreas HOLZINGER & Team
References:
[1] Holzinger, Andreas, Saranti, Anna & Mueller, Heimo 2021. KANDINSKYPatterns – An experimental exploration environment for Pattern Analysis and Machine Intelligence. https://arxiv.org/abs/2103.00519
[2] Project homepage: https://human-centered.ai/project/kandinsky-patterns
Assigned to: GROUP BKS
Mini Project 05: NeSy Concept Learner Playground (Part 1: Framework)
Goal: Provide a Framework for experimental work on KANDINSKYPatterns with the Neuro Symbolic Concept Learner.
Description: Explain Perturbation experiments on LRP, can it made easier for LSTMs processing text, because a word can be easier removed than an image area which is important / overlaps with an object, for example:
– Create unit tests for causality, check for compositionality [3],
– Experiment with NeSy concept learning approaches (as in [3] for compositionality, or as in [4] for XAI),
– e.g. those to be verified by DL Learner of description logic
Tasks: Use KandisnkyPatterns [1] as playground where we have full control of experiments and take baby steps, pick just two concepts for each group, create a grammar and try to adapt The Neuro Symbolic (NeSy) Concept Learner [2] on it. NN failing on those tasks is normal (as in Bongard-LOGO paper).
Tutors: Natalia Diaz RODRIGUEZ, Anna SARANTI, Andreas HOLZINGER & Team
References:
[1] Holzinger, A., Saranti, A. & Mueller, H. 2021. KANDINSKYPatterns – An experimental exploration environment for Pattern Analysis and Machine Intelligence. https://arxiv.org/abs/2103.00519
[2] Mao, J., Gan, C., Kohli, P., Tenenbaum, J. B. & Wu, J. 2019. The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision. https://arxiv.org/abs/1904.12584
[3] Hupkes, D., Dankers, V., Mul, M. & Bruni, E. 2020. Compositionality decomposed: how do neural networks generalise? Journal of Artificial Intelligence Research, 67, 757-795, doi:10.1613/jair.1.11674
[4] Aubin, B., Słowik, A., Arjovsky, M., Bottou, L. & Lopez-Paz, D. 2021. Linear unit-tests for invariance discovery. https://arxiv.org/abs/2102.10867
Assigned to: GROUP xx
Mini Project 06: NeSy Concept Learner Playground (Part 2: Practial Application)
Goal: Experimenting with multi-modal causability in the context of an application domain (Parasitology)
Description: What happens if this parasite increases in size? What would be the effect? What would happen if this develops further? What shape it will develop into? Background vs foreground causal explanations. From CLEVR dataset to lego blocks forming with KANDINSKYPatterns and later test in real-world data sets with pizza dataset or covid x-rays: lung vs background
Task: Align with Mini Project 02 and apply it to the field of Parasitology (domain expertise will be provided here from Natalia)
in connection with multi-modal causability [1]
Tutors: Natalia Diaz RODRIGUEZ, Domain Expert, Anna SARANTI, Andreas HOLZINGER & Team
References:
[1] Andreas Holzinger, Bernd Malle, Anna Saranti & Bastian Pfeifer (2021). Towards Multi-Modal Causability with Graph Neural Networks enabling Information Fusion for explainable AI. Information Fusion, 71, (7), 28-37, doi:10.1016/j.inffus.2021.01.008
Assigned to: GROUP xx
Mini Project 07: Does the explanation to machine learning affect user’s perception of fairness?
Goal: Find out whether and to what extent different xAI explanations affect the user perception of fairness in the context of decision making.
Description: This Mini Project is to delve into the investigation of a currently interesting and relevant question: whether different machine learning (ML) explanations [1], [2] affect user’s perception of fairness in ML-informed decision making? If so, how do ML explanations affect user’s perception of fairness [2]. This can be achieved by designing an on-line experiment by manipulating ML explanations in ML-informed decision making tasks. Participants need to be invited to conduct tasks in order to collect their responses of perception of fairness under different ML explanations. The collected data are then analysed (e.g. statistical analysis) to answer the respective research questions.
Tasks: 1) Design an experiment to understand relations between ML explanation and user’s perception of fairness in ML-information decision making. 2) Develop an online platform to collect user responses. 3) Analyse user responses to get insights.
Tutors: Jianlong ZHOU, Andreas HOLZINGER & Team
References:
[1] Vijay Arya, Rachel Bellamy, Pin-Yu Chen, Amit Dhurandhar, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Q. Vera Liao, Ronny Luss & Aleksandra Mojsilovic (2019). One explanation does not fit all: A toolkit and taxonomy of ai explainability techniques. https://arxiv.org/abs/1909.03012
[2] AI Explainability 360: extensible open source toolkit to help to comprehend how machine learning models predict labels by various means throughout the AI application lifecycle: http://aix360.mybluemix.net/
[3] J. A. Colquitt and J. B. Rodell (2015). Measuring Justice and Fairness. In: The Oxford Handbook of Justice in the Workplace, R. S. Cropanzano and M. L. Ambrose, Eds. Oxford University Press, 2015. Online available: https://www.academia.edu/39980020/Measuring_Justice_and_Fairness
Note: This topic is meanwhile taken seriously amoung the AI/ML community, a good sign for this is that this is taught in a regular machine learning class at MIT: https://www.youtube.com/watch?v=wmyVODy_WD8
Assigned to: GROUP AT
Mini Project 08: Evaluating BabyAI with a new Human-AI interface
Goal: Evaluate via online experiments the BabyAI platform with a newly designed human-AI interface.
Description: In times of a pandemic it is extremely difficult to experiment with humans in real-world situations. This makes experiments including the human-in-the-loop difficult. The BabyAI [1], [2] platform has been designed to measure the sample efficiency of training an agent to follow grounded-language instructions. Learning with a human in the loop [3] is an extremely important problem to study. The main counter-argument of engineers is “what is the human-in-the-loop supposed to do” … “to bring in human expertise, explicit knowledge, …” … “but how?”. This Mini Project shall contribute to the question of how to include a human-in-the-loop when a real-world setting is not possible, and with an evaluation mitigate the critics of the reviewers at ICML 2019 [4].
Task: Design and develop a human-in-the-loop interface to evaluate the BabyAI platform
Tutors: Andreas HOLZINGER
References:
[1] Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen & Yoshua Bengio (2018). BabyAI: A platform to study the sample efficiency of grounded language learning. https://arxiv.org/abs/1810.08272
[2] https://github.com/mila-iqia/babyai
[3] https://human-centered.ai/project/iml/
[4] “Interesting direction, but paper falls short of human evaluation” https://openreview.net/forum?id=rJeXCo0cYX
Assigned to GROUP: GH
Mini Project 09: Evaluation of Multi-Modal Embeddings and Graph Fusion
Goal: Evaluate various graph-based approaches to incorporate multi-modal disease relevant features into an embedded feature space.
Description: Complex diseases such as cancer need to be studied on a systems level, because the interplay of highly diverse modalities (DNA mutations, Gene expression, Methylation, etc.) substantially contributes to disease progression [1]. Here, graphs provide a natural way to efficiently model this phenomenon; however, semantic links between biological and disease-relevant features across modalities are largely unknown to this date.
Task: (1) Evaluate existing multi-modal embedding and graph fusion approaches via the state-of-the-art techniques developed in the field [2], (2) apply basic clustering methods to the obtained embedding spaces in order to group patients into medical relevant clusters, (3) benchmark the developed framework suitable to the future needs of multi-modal causability research [3].
Tutor: Andreas HOLZINGER and Team
References:
[1] Mika Gustafsson, Colm E. Nestor, Huan Zhang, Albert-László Barabási, Sergio Baranzini, Sören Brunak, Kian Fan Chung, Howard J. Federoff, Anne-Claude Gavin & Richard R. Meehan (2014). Modules, networks and systems medicine for understanding disease and aiding diagnosis. Genome medicine, 6, (10), 1-11, https://doi.org/10.1186/s13073-014-0082-6
[2] Giulia Muzio, Leslie O’Bray, Karsten Borgwardt (2020), Biological network analysis with deep learning, Briefings in Bioinformatics, 257, https://doi.org/10.1093/bib/bbaa257
[3] Andreas Holzinger, Bernd Malle, Anna Saranti & Bastian Pfeifer (2021). Towards Multi-Modal Causability with Graph Neural Networks enabling Information Fusion for explainable AI. Information Fusion, 71, (7), 28-37, doi:10.1016/j.inffus.2021.01.008
Assigned to: GROUP xx
Mini Project 10: Employing Random Forests on Graphs and the Efficient Visualization of their Decision Paths
Goal: Employ the Random Forest (RF) classifier on graphs by a modified sampling scheme of the node-features.
Description: RFs are widely used to find the most relevant features in highly dimensional data sets. Feature Selection is particularly important in biomarker research. Biomarker research aims to verify a minimal set of biological entities as a prognostic marker for disease progression.
Tasks: (1) 1) Modify the RF feature sampling scheme to obtain a set of mtr functional dependent features. 2) Evaluate the performance of the developed classifier on real-word cancer data. 3) Visualize the decision paths on the input graph.
Tutor: Andreas HOLZINGER and Team
References:
[1] Frauke Degenhardt, Stephan Seifert, Silke Szymczak, Evaluation of variable selection methods for random forests and omics data sets, Briefings in Bioinformatics, Volume 20, Issue 2, March 2019, Pages 492–503, https://doi.org/10.1093/bib/bbx124
Assigned to: GROUP xx
Mini Project 11: Evaluation of the Google What-if Tool (WIT)
Goal: Evaluate the WIT and test it particularly for the use of counterfactual explanations useful in the medical domain.
Description: The open What-if Tool (WIT) [1], [2] developed by the Google People+AI Research Group is intended for performance testing in hypothetical situations, to analyze the importance of different data features, and to visualize model behavior across multiple models and subsets of input data and for different ML fairness metrics.
Task: Evaluate existing multi-modal embeddings and graph fusion approaches via the state-of-the-art techniques developed in this field in the last seven years (from w2v to Graph-GANs) and benchmark them suitable to the future needs of multi-modal causability research [1].
Tutors: Andreas HOLZINGER, Team and Domain Experts
References:
[1] Wexler, J., Pushkarna, M., Bolukbasi, T., Wattenberg, M., Viégas, F. & Wilson, J. 2019. The what-if tool: Interactive probing of machine learning models. IEEE transactions on visualization and computer graphics, 26, (1), 56-65, doi: 10.1109/TVCG.2019.2934619
[2] https://github.com/PAIR-code/what-if-tool
Assigned to: GROUP S
Mini Project 12: On explainable survival prediction using regression analysis on genomic and incidence data
Goal: Continue the work in [3] with a focus on explainability, interpretability and causability.
Description:
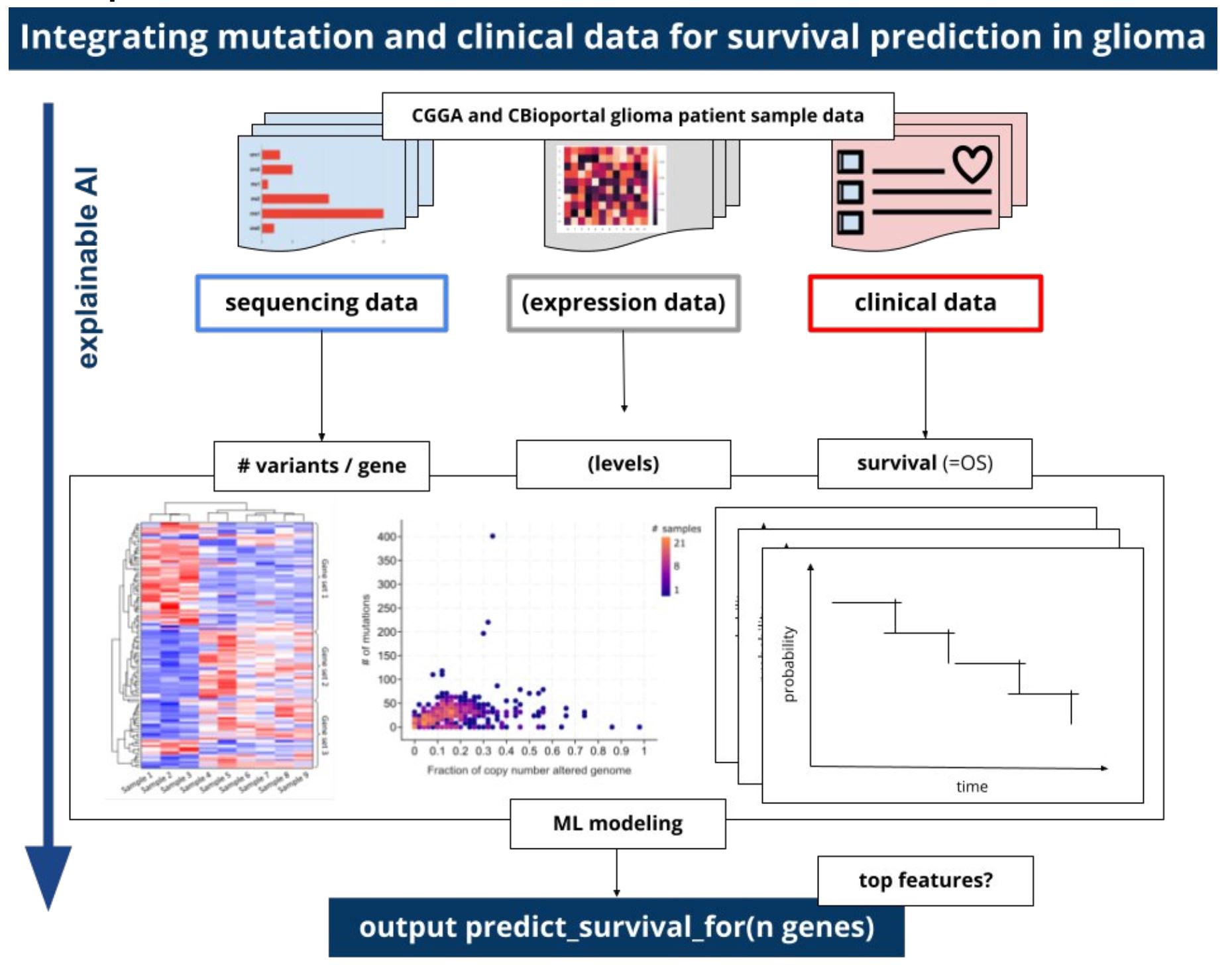
Tasks: Create Regression Implementation, Evaluate, Cross-Validate, Output Regression Table, find out which attribute(s) more important, output prediction and explanations.
Tutors: Fleur JEANQUARTIER and Claire JEAN-QUARTIER and Team
References:
[1] Baek, B. and Lee, H., 2020. Prediction of survival and recurrence in patients with pancreatic
cancer by integrating multi-omics data. Scientific reports, 10(1), 1-11, https://doi.org/10.1038/s41598-020-76025-1
[2] Guinney, J., Wang, T., Laajala, T. D., Winner, K. K., Bare, J. C., Neto, E. C., Khan, S. A., Peddinti, G., Airola, A. & Pahikkala, T. 2017. Prediction of overall survival for patients with metastatic castration-resistant prostate cancer: development of a prognostic model through a crowdsourced challenge with open clinical trial data. The Lancet Oncology, 18, (1), 132-142, https://doi.org/10.1016/S1470-2045(16)30560-5
[3] Jean-Quartier, C., Jeanquartier, F., Ridvan, A., Kargl, M., Mirza, T., Stangl, T., Markaĉ, R., Jurada, M. & Holzinger, A. 2021. Mutation-based clustering and classification analysis reveals distinctive age groups and age-related biomarkers for glioma. BMC Medical Informatics and Decision Making, 21, (1), 1-14, https://doi.org/10.1186/s12911-021-01420-1
Assigned to: GROUP xx
Mini Project 13: Beyond SHAP and LIME for explainability visualization
Goal: Identify and compare alternative python libraries to SHAP and LIME for explainability visualization.
Description:

Tasks: Compare different Python libraries for their suitability to visually explain decisions made by some selected ML algorithms.
Tutors: Fleur JEANQUARTIER and Claire JEAN-QUARTIER and Team
References:
[1] https://bjlkeng.github.io/posts/model-explanability-with-shapley-additive-explanations-shap
[3] https://www.betterdatascience.com/lime/
[4] Man, X. and Chan, E.P., 2021. The Best Way to Select Features? Comparing MDA, LIME, and SHAP. The Journal of Financial Data Science, 3(1), 127-139, https://doi.org/10.3905/jfds.2020.1.047
[5] https://mltooling.substack.com/p/top-5-model-interpretability-libraries
[6] Jean-Quartier, C., Jeanquartier, F., Ridvan, A., Kargl, M., Mirza, T., Stangl, T., Markaĉ, R., Jurada, M. & Holzinger, A. 2021. Mutation-based clustering and classification analysis reveals distinctive age groups and age-related biomarkers for glioma. BMC Medical Informatics and Decision Making, 21, (1), 1-14, https://doi.org/10.1186/s12911-021-01420-1
Assigned to: GROUP GJV
Mini Project 14: Interpretable Machine Learning with REMBRANDT project image data and survival numbers
Goal: Experiment and analyse survival numbers to predict survival for image input with a focus on explainability and causability
Description:
Tasks: Correlate image data with survival numbers to predict survival for image input and experiment towards better explainability and causability
Tutors: Fleur JEANQUARTIER and Claire JEAN-QUARTIER and Team
References:
[1] Gusev, Y., Bhuvaneshwar, K., Song, L., Zenklusen, J.C., Fine, H. and Madhavan, S., 2018.
The REMBRANDT study, a large collection of genomic data from brain cancer
patients. Scientific data, 5( 1), pp.1-9, https://doi.org/10.1038/sdata.2018.158
[2] Pope, W.B., Sayre, J., Perlina, A., Villablanca, J.P., Mischel, P.S. and Cloughesy, T.F., 2005.
MR imaging correlates of survival in patients with high-grade gliomas. American Journal of
Neuroradiology, 26 (10), pp. 2466-2474 http://www.ajnr.org/content/26/10/2466.full
[3] Wu, C.C., Jain, R., Radmanesh, A., Poisson, L.M., Guo, W.Y., Zagzag, D., Snuderl, M.,
Placantonakis, D.G., Golfinos, J. and Chi, A.S., 2018. Predicting genotype and survival in
glioma using standard clinical MR imaging apparent diffusion coefficient images: a pilot study
from the cancer genome atlas. American Journal of Neuroradiology, 39 (10), pp.1814-1820 http://www.ajnr.org/content/39/10/1814.abstract
[4] Pintelas, E., Liaskos, M., Livieris, I.E., Kotsiantis, S. and Pintelas, P., 2020. Explainable
Machine Learning Framework for Image Classification Problems: Case Study on Glioma Cancer
Prediction. Journal of Imaging, 6 (6), https://doi.org/10.3390/jimaging6060037
Assigned to: GROUP EM
Mini Project 15: Finding automatisms for data mining survival data in glioma publications
Goal: To produce a dataset of kaplan-meier curves or respecitve survival data for regression analysis
Description: Identify possibilities to mine survival data from various repositories such as europe PMC and/or others as ACM, IEEE Xplore, Springer, ScienceDirect, Scopus, and Wiley online library. Mine data and store with source as meta attribute to create a set of Kaplan-Meier curves from glioma samples. This set can than be highly useful for the international research community for improving regression analysis and prediction of glioma survival.
Tasks: Start with a systematic literature review (SLR), on that basis use, adapt, develop and experiment with different data mining algorithms with the output of a dataset of kaplan-meier curves or respective survival data for regression analysis.
Tutors: Fleur JEANQUARTIER and Claire JEAN-QUARTIER and Team
References:
[1] Riedel, N., Kip, M. and Bobrov, E., 2020. ODDPub – a Text-Mining Algorithm to Detect Data Sharing in Biomedical Publications. Data Science Journal, 19(1), p.42. http://doi.org/10.5334/dsj-2020-042
[2] Spasić, I., Livsey, J., Keane, J.A. and Nenadić, G., 2014. Text mining of cancer-related information: review of current status and future directions. International journal of medical informatics, 83(9), 605-623.
[3] Antons, D., Grünwald, E., Cichy, P. and Salge, T.O., 2020. The application of text mining methods in innovation research: current state, evolution patterns, and development priorities. R&D Management, 50(3), pp.329-351.
[4] Adnan, K. and Akbar, R., 2019. An analytical study of information extraction from unstructured and multidimensional big data. Journal of Big Data, 6(1), pp.1-38.
[5] Przybyła, P., Shardlow, M., Aubin, S., Bossy, R., Eckart de Castilho, R., Piperidis, S., McNaught, J. and Ananiadou, S., 2016. Text mining resources for the life sciences. Database: The journal of Biological Databases and Curation. baw 145, https://doi.org/10.1093/database/baw145
Assigned to: GROUP xx
Mini Project 16: Federated Learning in Digital Pathology
Goal: To build and evaluate a Federated Learning Web application for digital pathology.
Description: Federated Learning [1] is a collaborative model training paradigm, where distributed users train local models [2] with local data and update a centralised model, without needing to share any data. This puts privacy at the focus of the machine learning approach. Privacy is particularly important in the medical domain, where the sharing of data between institutions is often not possible. Therefore, machine learning models that are trained at a certain institution may be biased towards the data collection practices or workflows that are local to that institution and may not generalise well. In this Mini Project we will build a web-based front-end for a digital pathology application using the Federated Learning approach. The app should provide a front-end for users allowing them to tag images and regions from Whole Slides Images (WSI) from digital pathology [3], and these tags will be used to train a centralised model.
Tasks: To build the application we will use TensorFlow Federated for the network training (see https://www.tensorflow.org/federated) and HTML/Bootstrap/JavaScript to build a front-end. The server-side code should be written in Python, as we will use the Flask web server framework. Therefore, prerequisites would be some experience developing in Python and JavaScript and some knowledge of training neural networks with a framework such as TensorFlow or Keras. The main tasks can be broken in to three main milestones:
- Milestone 1: Working UI built using Bootstrap, jQuery, JavaScript, using Flask Web server;
- Milestone 2: Simple federated neural network using the MNIST data set, which serves as a good data set to verify the approach is working;
- Milestone 3: Final UI, federated learning application working with real data, deployable to test users
Tutors: Marcus BLOICE and Team
References:
[1] Sattler, F., Wiedemann, S., Müller, K.-R. & Samek, W. 2019. Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems, 31, (9), 3400-3413, https://doi.org/10.1109/TNNLS.2019.2944481
[2] Malle, B., Giuliani, N., Kieseberg, P. & Holzinger, A. 2017. The More the Merrier – Federated Learning from Local Sphere Recommendations. Machine Learning and Knowledge Extraction, Lecture Notes in Computer Science LNCS 10410 Cham: Springer, pp. 367-374, https://doi.org/10.1007/978-3-319-66808-6_24
[3] Holzinger, A., Malle, B., Kieseberg, P., Roth, P. M., Müller, H., Reihs, R. & Zatloukal, K. 2017. Towards the Augmented Pathologist: Challenges of Explainable-AI in Digital Pathology. https://arxiv.org/abs/1712.06657
Assigned to: GROUP M
Mini Project 17: Synthetic textual descriptions for KANDINSKYPatterns (KP)
Goal: Conceive an appropriate grammar or domain-specific language to describe KP
Description: Textual descriptions of KP images can be synthetically generated, obeying the rules of grammar or domain-specific language. Other concept learning benchmark datasets listed in section 3.2. of [1] have similar grammars that express the selected concepts. Since images of KP can belong to several concepts at the same time, it is highly likely that the definition of a probabilistic grammar [2], [3] will be necessary.
Tasks: Go briefly through the datasets listed in section 3.2. of [1], note the grammars used and the principles on which they were conceived. Select simple KP first, create the most simple grammar and check for consistency. Generate example descriptions from this grammar. Add new KP and iterate the procedure.
Tutors: Anna SARANTI, Andreas HOLZINGER & Team
References:
[1] Holzinger, A., Saranti, A. & Mueller, H. 2021. KANDINSKYPatterns – An experimental exploration environment for Pattern Analysis and Machine Intelligence. https://arxiv.org/abs/2103.00519
[2] Aksoy, S., Koperski, K., Tusk, C., Marchisio, G. & Tilton, J. C. 2005. Learning Bayesian classifiers for scene classification with a visual grammar. IEEE Transactions on geoscience and remote sensing, 43, (3), 581–589, doi:10.1109/TGRS.2004.839547 Semantic Scholar
[3] Pu, X. & Kay, M. A probabilistic grammar of graphics. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 2020. 1-13, https://doi.org/10.1145/3313831.3376466
Assigned to: GROUP xx
Mini Project 18: Explaining via short quantified sentences of natural language
Goal: Develop a model and front-end application for explaining data by short quantified sentences of natural language
Description: Verbal explanations are important for the emerging field of explainable AI. Less statistically literate users (e.g., domain experts) can benefit from linguistic summarization. Summaries including, e.g., “most of entities of high value of P have low value of S” (where P and S are atomic or compound predicates) can be understood by humans immediately. Instead of quantifier (Q) “most of”, we can apply other elastic quantifiers such as “few” and “about half”. Quantifiers and adjectives can be expressed by linear functions (simple but effective). Although such structures are theoretically covered and used, the main problem is learning all relevant summarized sentences from data to produce meaningful storytelling filtered by the quality measures.
Tasks: In this Mini Project, the task is to reveal (all) relevant (ideally surprising) sentences. Theoretically, this would require an enormous number of proportions in data to be checked. Here only a machine learning approach can help in this direction, i.e., to find all relevant combinations of Q, R, S of a sufficient quality on the key subset of attributes (dimensions). A promising direction is learning proportions to produce relevant sentences. Generally, data can be of any type, but for the experimental purposes, numerical and categorical data are sufficient. The model should be independent on data types, because summaries rely on the intensities to belonging to the concepts, e.g., a value of pressure to the concept high pressure, or the number of red marks on an image to the concept high density of red marks.
Tutors: Miroslav HUDEC & Team
References:
[1] Hudec, M., Bednárová, E. & Holzinger, A. 2018. Augmenting Statistical Data Dissemination by Short Quantified Sentences of Natural Language. Journal of Official Statistics (JOS), 34, (4), 981, https://doi.org/10.2478/jos-2018-0048
Assigned to: GROUP xx
Mini Project 19: Classification into classes by aggregation functions of mixed behaviour
Goal: Explore the benefits and weaknesses of aggregation functions of mixed behaviour in learning how to classify into the classes “yes”, “no” and “maybe” (considering inclination towards “yes” or “no”).
Prerequisites and interests: knowledge discovery from data, logic, data mining, programming
Description: Classification by rule-based systems rely on IF-THEN rules posed by domain expert. Although efficient, it might be a tedious task for domain expert. Supervised classification by ML requires labelled attribute, a large data set of a sufficient quality (i.e., covering the whole domain of possible values) and the solution is not explainable, but it is a very efficient way. An answer might be classification by aggregation functions of mixed behaviour (conjunctive, disjunctive and averaging on parts of domains). Domain expert is able to provide explanations linguistically like: “when value of attribute A is (very) high and value of attribute B is (very) low the concern is full, when value of attribute A is (rather) low and value of attribute B is (rather) high there is no reason for concern, otherwise a medium concern is raised, and similar entities should be similarly treated.”
Tasks: Recognize the suitable classes of functions and classify even when a low amount of data is available. In the case of a larger data set, iML for adjusting parameters of the chosen functions should be applied. Next, the effects of atomic and compound predicates, various data types and aggregation functions should be evaluated considering their ability in learning from data.
Tutors: Miroslav HUDEC & Team
References:
[1] Hudec, M., Minarikova, E., Mesiar, R., Saranti, A. & Holzinger, A. 2021. Classification by ordinal sums of conjunctive and disjunctive functions for explainable AI and interpretable machine learning solutions. Knowledge Based Systems, https://doi.org/10.1016/j.knosys.2021.106916
Assigned to: GROUP GK
Some background reading:
Intelligent User Interfaces (IUI) is where Human-computer interaction (HCI) meet Artificial Intelligence (AI). This is often defined as the design of intelligent agents, which is the core essence in Machine Learning (ML). In interactive Machine Learning (iML) this agents can also be humans:
Holzinger, A. 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Springer Brain Informatics (BRIN), 3, (2), 119-131, doi:10.1007/s40708-016-0042-6.
Online: https://link.springer.com/article/10.1007/s40708-016-0042-6
Holzinger, A. 2016. Interactive Machine Learning (iML). Informatik Spektrum, 39, (1), 64-68, doi:10.1007/s00287-015-0941-6.
Online: https://link.springer.com/article/10.1007/s00287-015-0941-6
Holzinger, A., et al. 2017. A glass-box interactive machine learning approach for solving NP-hard problems with the human-in-the-loop. arXiv:1708.01104.
Online: https://arxiv.org/abs/1708.01104
Holzinger, A., et al. 2017. What do we need to build explainable AI systems for the medical domain? arXiv:1712.09923.
Online: https://www.groundai.com/project/what-do-we-need-to-build-explainable-ai-systems-for-the-medical-domain
Holzinger, A. 2018. Explainable AI (ex-AI). Informatik-Spektrum, 41, (2), 138-143, doi:10.1007/s00287-018-1102-5.
Online: https://link.springer.com/article/10.1007/s00287-018-1102-5
Holzinger, A., et al. 2018. Interactive machine learning: experimental evidence for the human in the algorithmic loop. Applied Intelligence, doi:10.1007/s10489-018-1361-5.
Online: https://link.springer.com/article/10.1007/s10489-018-1361-5
In this practically oriented course, Software Engineering is seen as dynamic, interactive and cooperative process which facilitate an optimal mixture of standardization and tailor-made solutions. Here you have the chance to work on real-world problems (on the project digital pathology).
Previous knowledge expected
Interest in experimental Software Engineering in the sense of:
Science is to test crazy ideas – Engineering is to put these ideas into Business.
Interest in cross-disciplinary work, particularly in the HCI-KDD approach: Many novel discoveries and insights are found at the intersection of two domains, see: A. Holzinger, 2013. “Human–Computer Interaction and Knowledge Discovery (HCI-KDD): What is the benefit of bringing those two fields to work together?“, in Multidisciplinary Research and Practice for Information Systems, Springer Lecture Notes in Computer Science LNCS 8127, A. Cuzzocrea, C. Kittl, D. E. Simos, E. Weippl, and L. Xu, Eds., Heidelberg, Berlin, New York: Springer, pp. 319-328. [DOI] [Download pdf]
General guidelines for the technical report
Holzinger, A. (2010). Process Guide for Students for Interdisciplinary Work in Computer Science/Informatics. Second Edition. Norderstedt: BoD (128 pages, ISBN 978-3-8423-2457-2)
also available at Fachbibliothek Inffeldgasse.
Technical report templates
Please use the following templates for your scientific paper:
(new) A general LaTeX template can be found on overleaf > https://www.overleaf.com/4525628ngbpmv
Further information and templates available at: Springer Lecture Notes in Computer Science (LNCS)
Review template 2020
REVIEW-TEMPLATE-2020-XXXX (Word-doc 342 kB)
REVIEW-TEMPLATE-2020-XXXX (pdf, 143 kB)