



Recent advances in automatic machine learning (aML) allow solving problems without any human intervention, which is excellent in certain domains, e.g. in autonomous cars, where we want to exclude the human from the loop and want fully automatic learning. However, sometimes a human-in-the-loop can be beneficial – particularly in solving computationally hard problems. We provide new experimental insights [1] on how we can improve computational intelligence by complementing it with human intelligence in an interactive machine learning approach (iML). For this purpose, an Ant Colony Optimization (ACO) framework was used, because this fosters multi-agent approaches with human agents in the loop. We propose unification between the human intelligence and interaction skills and the computational power of an artificial system. The ACO framework is used on a case study solving the Traveling Salesman Problem, because of its many practical implications, e.g. in the medical domain. We used ACO due to the fact that it is one of the best algorithms used in many applied intelligence problems. For the evaluation we used gamification, i.e. we implemented a snake-like game called Traveling Snakesman with the MAX–MIN Ant System (MMAS) in the background. We extended the MMAS–Algorithm in a way, that the human can directly interact and influence the ants. This is done by “traveling” with the snake across the graph. Each time the human travels over an ant, the current pheromone value of the edge is multiplied by 5. This manipulation has an impact on the ant’s behavior (the probability that this edge is taken by the ant increases). The results show that the humans performing one tour through the graphs have a significant impact on the shortest path found by the MMAS. Consequently, our experiment demonstrates that in our case human intelligence can positively influence machine intelligence. To the best of our knowledge this is the first study of this kind and it is a wonderful experimental platform for explainable AI.
[1] Holzinger, A. et al. (2018). Interactive machine learning: experimental evidence for the human in the algorithmic loop. Springer/Nature: Applied Intelligence, doi:10.1007/s10489-018-1361-5.
Read the full article here:
https://link.springer.com/article/10.1007/s10489-018-1361-5

The second Volume of the Springer LNCS Proceedings of the IFIP TC 5, TC 8/WG 8.4, 8.9, TC 12/WG 12.9 International Cross-Domain Conference, CD-MAKE Machine Learning & Knowledge Extraction just appeared, see:
https://link.springer.com/book/10.1007/978-3-319-99740-7
>> Here the preprints of our papers:
[1] Andreas Holzinger, Peter Kieseberg, Edgar Weippl & A Min Tjoa 2018. Current Advances, Trends and Challenges of Machine Learning and Knowledge Extraction: From Machine Learning to Explainable AI. Springer Lecture Notes in Computer Science LNCS 11015. Cham: Springer, pp. 1-8, doi:10.1007/978-3-319-99740-7_1.
HolzingerEtAl2018_from-machine-learning-to-explainable-AI-pre (pdf, 198 kB)
[2] Randy Goebel, Ajay Chander, Katharina Holzinger, Freddy Lecue, Zeynep Akata, Simone Stumpf, Peter Kieseberg & Andreas Holzinger. Explainable AI: the new 42? Springer Lecture Notes in Computer Science LNCS 11015, 2018 Cham. Springer, 295-303, doi:10.1007/978-3-319-99740-7_21.
GOEBEL et al (2018) Explainable-AI-the-new-42 (pdf, 835 kB)
Here the link to the bookmetrix page:
https://www.bookmetrix.com/detail/book/38a3a435-ab77-4db9-a4ad-97ce63b072b3#citations
>> From the preface:
Each paper was assigned to at least three reviewers of our international scientific committee; after review and metareview and editorial decision they carefully selected 25 papers for this volume out of 75 submissions in total, which resulted in an acceptance rate of 33 %.
The International Cross-Domain Conference for Machine Learning and Knowledge Extraction, CD-MAKE, is a joint effort of IFIP TC 5, TC 12, IFIP WG 8.4, IFIP WG 8.9 and IFIP WG 12.9 and is held in conjunction with the International Conference on Availability, Reliability and Security (ARES).
IFIP – the International Federation for Information Processing – is the leading multinational, non-governmental, apolitical organization in information and communications technologies and computer sciences, is recognized by the United Nations (UN) and was established in the year 1960 under the auspices of UNESCO as an outcome of the first World Computer Congress held in Paris in 1959. IFIP is incorporated in Austria by decree of the Austrian Foreign Ministry (September 20, 1996, GZ 1055.170/120-I.2/96) granting IFIP the legal status of a non-governmental international organization under the Austrian Law on the Granting of Privileges to Non-Governmental International Organizations (Federal Law Gazette 1992/174).
IFIP brings together more than 3,500 scientists without boundaries from both academia and industry, organized in more than 100 Working Groups (WGs) and 13 Technical Committees (TCs). CD stands for “cross-domain” and means the integration and appraisal of different fields and application domains to provide an atmosphere to foster different perspectives and opinions.
The conference fosters an integrative machine learning approach, taking into account the importance of data science and visualization for the algorithmic pipeline with a strong emphasis on privacy, data protection, safety, and security.
It is dedicated to offering an international platform for novel ideas and a fresh look at methodologies to put crazy ideas into business for the benefit of humans. Serendipity is a desired effect and should lead to the cross-fertilization of methodologies and the transfer of algorithmic developments.
The acronym MAKE stands for “MAchine Learning and Knowledge Extraction,” a field that, while quite old in its fundamentals, has just recently begun to thrive based on both the novel developments in the algorithmic area and the availability of big data and vast computing resources at a comparatively low price.
Machine learning studies algorithms that can learn from data to gain knowledge from experience and to generate decisions and predictions. A grand goal is to understand intelligence for the design and development of algorithms that work autonomously (ideally without a human-in-the-loop) and can improve their learning behavior over time. The challenge is to discover relevant structural and/or temporal patterns (“knowledge”) in data, which are often hidden in arbitrarily high-dimensional spaces, and thus simply not accessible to humans. Machine learning as a branch of artificial intelligence is currently undergoing a kind of Cambrian explosion and is the fastest growing field in computer science today.
There are many application domains, e.g., smart health, smart factory (Industry 4.0), etc. with many use cases from our daily lives, e.g., recommender systems, speech recognition, autonomous driving, etc. The grand challenges lie in sense-making, in context-understanding, and in decisionmaking under uncertainty.
Our real world is full of uncertainties and probabilistic inference had an enormous influence on artificial intelligence generally and statistical learning specifically. Inverse probability allows us to infer unknowns, to learn from data, and to make predictions to support decision-making. Whether in social networks, recommender systems, health, or Industry 4.0 applications, the increasingly complex data sets require efficient, useful, and useable solutions for knowledge discovery and knowledge extraction.
We cordially thank all members of the committee, reviewers, authors, supporters and friends! See you in Hamburg:
 Image taken by Andreas Holzinger
Image taken by Andreas Holzinger

The group around Tom GRIFFITHS *) from the Cognitive Science Lab at Berkeley recently asked in their paper by Rachit Dubey, Pulkit Agrawal, Deepak Pathak, Thomas L. Griffiths & Alexei A. Efros 2018. Investigating Human Priors for Playing Video Games. arXiv:1802.10217: “What makes humans so good at solving seemingly complex video games?”.
(Spoiler short answer in advance: we don’t know – but we can gradually improve our understanding on this topic).
The authors did cool work on investigating the role of human priors for solving video games. On the basis of a specific game, they conducted a series of ablation-studies to quantify the importance of various priors on human performance. For this purpose they modifyied the video game environment to systematically mask different types of visual information that could be used by humans as prior data. The authors found that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Their results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play.
Read the original paper here:
https://arxiv.org/abs/1802.10217
Or at least glance it over via the ArxiV sanity preserver by Andrew KARPATHY:
https://www.arxiv-sanity.com/search?q=+Investigating+Human+Priors+for+Playing+Video+Games
Videos and the game manipulations are available here:
https://rach0012.github.io/humanRL_website
*) Tom Griffiths is Professor of Psychology and Cognitive Science and is interested in developing mathematical models of higher level cognition, and understanding the formal principles that underlie human ability to solve the computational problems we face in everyday life. His current focus is on inductive problems, such as probabilistic reasoning, learning causal relationships, acquiring and using language, and inferring the structure of categories. He tries to analyze these aspects of human cognition by comparing human behavior to optimal or “rational” solutions to the underlying computational problems. For inductive problems, this usually means exploring how ideas from artificial intelligence, machine learning, and statistics (particularly Bayesian statistics) connect to human cognition.
See the homepage of Tom here:

A long time ago submitted paper from the Stan developers
https://mc-stan.org/
has finally been appeared at the Journal of statistical software:
https://www.jstatsoft.org
Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M. A., Guo, J., Li, P. & Riddell, A. 2017. Stan: A probabilistic programming language. Journal of Statistical Software, 76, (1), 1-32, doi:10.18637/jss.v076.i01
Also the Python package can be downloaded from the site!
Stan is a probabilistic programming language for specifying statistical models. A Stan program imperatively defines a log probability function over parameters conditioned on specified data and constants. Stan provides full Bayesian inference
for continuous-variable models through Markov chain Monte Carlo methods such as the No-U-Turn sampler, an adaptive form of Hamiltonian Monte Carlo sampling. Penalized maximum likelihood estimates are calculated using optimization methods such as the limited memory Broyden-Fletcher-Goldfarb-Shanno algorithm. Stan is also a platform for computing log densities and their gradients and Hessians, which can be used in alternative algorithms such as variational Bayes, expectation propagation, and marginal inference using approximate integration. To this end, Stan is set up so that the densities, gradients, and Hessians, along with intermediate quantities of the algorithm such as acceptance probabilities, are easily accessible. Stan can be called from the command line using the cmdstan package, through R using the rstan package, and through Python using the pystan package. All three interfaces support sampling and optimization-based inference with diagnostics and posterior analysis. rstan and pystan also provide access to log probabilities, gradients, Hessians, parameter transforms, and specialized plotting.
Congratulations from the Holzinger Group to the authors!

14.12.2016 LNAI 9605 just appeared
Machine Learning for Health Informatics Lecture Notes in Artificial Intelligence LNAI 9605
Holzinger, Andreas (ed.) 2016. Machine Learning for Health Informatics: State-of-the-Art and Future Challenges. Cham: Springer International Publishing, doi:10.1007/978-3-319-50478-0
Machine learning (ML) is the fastest growing field in computer science, and Health Informatics (HI) is amongst the greatest application challenges, providing future benefits in improved medical diagnoses, disease analyses, and pharmaceutical development. However, successful ML for HI needs a concerted effort, fostering integrative research between experts ranging from diverse disciplines from data science to visualization.
Tackling complex challenges needs both disciplinary excellence and cross-disciplinary networking without any boundaries. Following the HCI-KDD approach, in combining the best of two worlds, it is aimed to support human intelligence with machine intelligence.
This state-of-the-art survey is an output of the international HCI-KDD expert network and features 22 carefully selected and peer-reviewed chapters on hot topics in machine learning for health informatics; they discuss open problems and future challenges in order to stimulate further research and international progress in this field.

Our crazy iML-Concept has been accepted at the CiML 2016 workshop (organized by Isabelle Guyon, Evelyne Viegas, Sergio Escalera, Ben Hammer & Balazs Kegl) at NIPS 2016 (December, 5-10, 2016) in Barcelona:
Machine learning (ML) is the fastest growing field in computer science, and health informatics is among the greatest challenges. The goal of ML is to develop algorithms which can learn and improve over time and can be used for predictions. Most ML researchers concentrate on automatic machine learning (aML), where great advances have been made, for example, in speech recognition, recommender systems, or autonomous vehicles. Automatic approaches greatly benefit from big data with many training sets. However, in the health domain, sometimes we are confronted with a small number of data sets or rare events, where aML-approaches suffer of insufficient training samples. Here interactive machine learning (iML) may be of help, having its roots in reinforcement learning, preference learning, and active learning. The term iML is not yet well used, so we define it as “algorithms that can interact with agents and can optimize their learning behavior through these interactions, where the agents can also be human.” This “human-in-the-loop” can be beneficial in solving computationally hard problems, e.g., subspace clustering, protein folding, or k-anonymization of health data, where human expertise can help to reduce an exponential search space through heuristic selection of samples. Therefore, what would otherwise be an NP-hard problem, reduces greatly in complexity through the input and the assistance of a human agent involved in the learning phase. Most of all the human in the loop can bring in conceptual knowledge, “intuition”, expertise and explicit knowledge which current AI is completely lacking!
We define iML-approaches as algorithms that can interact with both computational agents and human agents *) and can optimize their learning behavior through these interactions.
*) In active learning such agents are referred to as the so-called “oracles”
The first question we have to answer is: “What is the difference between the iML-approach to the aML-approach, i.e., unsupervised learning, supervised, or semi-supervised learning?”
Scenario D – see slide below – shows the iML-approach, where the human expert is seen as an agent directly involved in the actual learning phase, step-by-step influencing measures such as distance, cost functions, etc.
Obvious concerns may emerge immediately and one can argue: what about the robustness of this approach, the subjectivity, the transfer of the (human) agents; many questions remain open and are subject for future research, particularly in evaluation, replicability, robustness, etc.
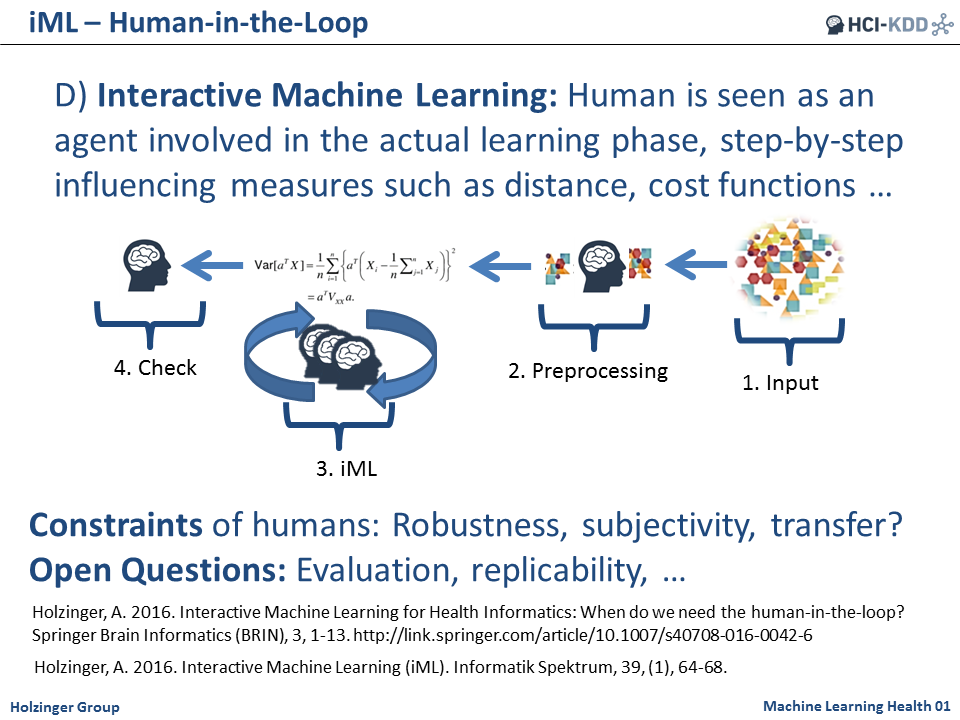
The iML-approach
Read full article here:
https://link.springer.com/article/10.1007/s40708-016-0042-6/fulltext.html
https://www.mendeley.com/catalog/interactive-machine-learning-health-informatics-we-need-humanintheloop
