Federated Collaborative Machine Learning
The Google Research Group [1] is always doing awesome stuff, the most recent one is on Federated Learning [2], which enables e.g. smart phones (of course any computational device, and maybe later all internet-of-things, intelligent sensors in either smart hospitals or in smart factories etc.) to collaboratively learn a shared representation model, whilst keeping all the training data on the local devices, decoupling the ability to do machine learning from the need to store the data centralized in the cloud. This goes beyond the use of local models that make predictions on mobile devices (like the Mobile Vision API and On-Device Smart Reply) by bringing model training to the device as well – which is great. The problem with standard approaches is that you always need centralized training data – either on your USB-stick, as the medical doctors do, or in a sophisticated centralized data center.
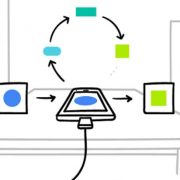
The basic idea is that the mobile device downloads the current modela and subsequently improves it by learning from data on the respective device, and then summarizes the changes as a small focused update. The remarkable detail is that only this update to the model is sent to the cloud (yes, here privacy, data protection safety and security is challenged see e.g. [3] – but this is much easier to do with this small data – as when you would do it with the raw data – think for example on patient data), where it is immediately averaged with other devicer updates to improve the shared model. All the training data remains on the local devices, and no individual updates are stored in the cloud.
The Google Group recently solved a lot of algorithmic and technical challenges. In a typical machine learning system, an optimization algorithm e.g. Stochastic Gradient Descent (SGD) [4] runs on a large dataset partitioned homogeneously across servers in the cloud. Such highly iterative algorithms require low-latency, high-throughput connections to the training data. But in the Federated Learning setting, the data is distributed across millions of devices in a highly uneven fashion. In addition, these devices have significantly higher-latency, lower-throughput connections and are only intermittently available for training.
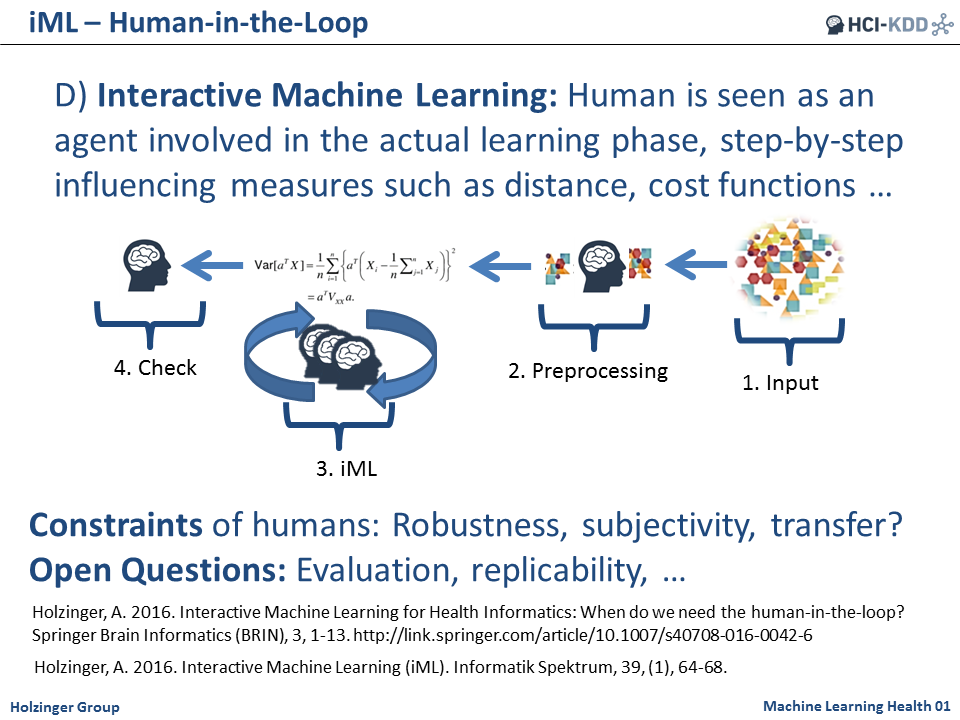
This calls for a lot of further investigations with interactive Machine Learning (iML) bringing the human-into-the loop, i.e. making use of human cognitive abilities. This can be of particular interest to solve problems, where learning algorithms suffer due to insufficient training samples (rare events, single events), where we deal with complex data and/or computationally hard problems. For example, “doctors-in-the-loop” can help with their long-term experience and heursitic knowledge to solve problems which otherwise would remain NP-hard [5, 6]. A further step is with many humans-in-the-loop: Such collaborative interactive Machine Learning (ciML) can help in many application areas and domains, e.g. in in health informatics (smart hospital) or in industrial applications (smart factory) [7].
Read the original article, posted on April, 6, 2017, here:
https://research.googleblog.com/2017/04/federated-learning-collaborative.html
[1] https://research.googleblog.com
[2] NIPS Workshop on Private Multi-Party Machine Learning, Barcelona, December, 9, 2016, https://pmpml.github.io/PMPML16/
[3] Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., Mcmahan, H. B., Patel, S., Ramage, D., Segal, A. & Seth, K. 2016. Practical Secure Aggregation for Federated Learning on User-Held Data. arXiv preprint arXiv:1611.04482.
[4] Bottou, L. 2010. Large-scale machine learning with stochastic gradient descent. Proceedings of COMPSTAT’2010. Springer, pp. 177-186. doi:10.1007/978-3-7908-2604-3_16 (N.B.: 836 citations as of 08.04.2017)
[5] Holzinger, A. 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Brain Informatics, 3, (2), 119-131, doi:10.1007/s40708-016-0042-6
[6] Holzinger, A., Plass, M., Holzinger, K., Crisan, G., Pintea, C. & Palade, V. 2016. Towards interactive Machine Learning (iML): Applying Ant Colony Algorithms to solve the Traveling Salesman Problem with the Human-in-the-Loop approach. In: Springer Lecture Notes in Computer Science LNCS 9817. Heidelberg, Berlin, New York: Springer, pp. 81-95, [pdf]
[7] Robert, S., Büttner, S., Röcker, C. & Holzinger, A. 2016. Reasoning Under Uncertainty: Towards Collaborative Interactive Machine Learning. In: Machine Learning for Health Informatics: Lecture Notes in Artifical Intelligence LNAI 9605. Springer, pp. 357-376, [pdf]
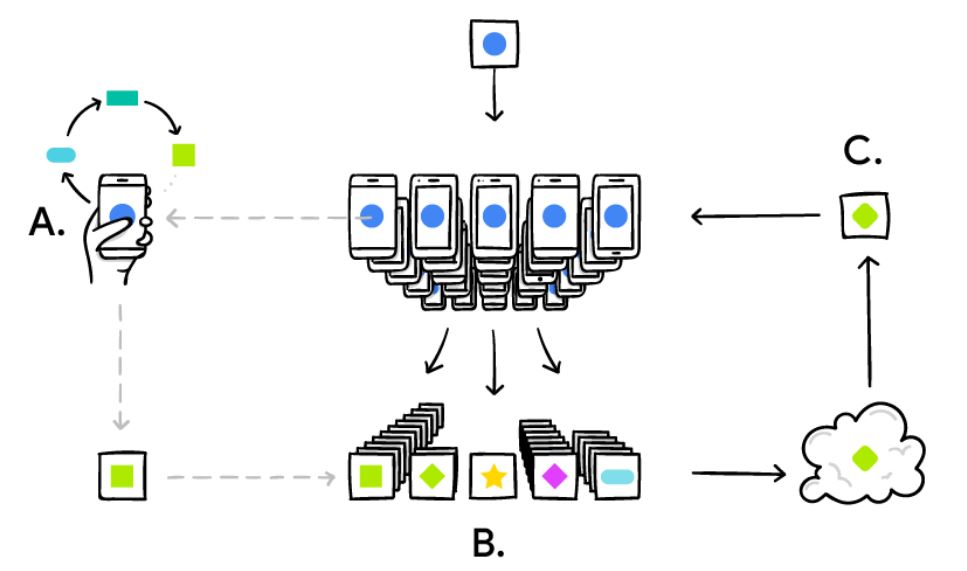 Image source: https://research.googleblog.com/2017/04/federated-learning-collaborative.html
Image source: https://research.googleblog.com/2017/04/federated-learning-collaborative.html