Recent advances in automatic machine learning (aML) allow solving problems without any human intervention, which is excellent in certain domains, e.g. in autonomous cars, where we want to exclude the human from the loop and want fully automatic learning. However, sometimes a human-in-the-loop can be beneficial – particularly in solving computationally hard problems. We provide new experimental insights [1] on how we can improve computational intelligence by complementing it with human intelligence in an interactive machine learning approach (iML). For this purpose, an Ant Colony Optimization (ACO) framework was used, because this fosters multi-agent approaches with human agents in the loop. We propose unification between the human intelligence and interaction skills and the computational power of an artificial system. The ACO framework is used on a case study solving the Traveling Salesman Problem, because of its many practical implications, e.g. in the medical domain. We used ACO due to the fact that it is one of the best algorithms used in many applied intelligence problems. For the evaluation we used gamification, i.e. we implemented a snake-like game called Traveling Snakesman with the MAX–MIN Ant System (MMAS) in the background. We extended the MMAS–Algorithm in a way, that the human can directly interact and influence the ants. This is done by “traveling” with the snake across the graph. Each time the human travels over an ant, the current pheromone value of the edge is multiplied by 5. This manipulation has an impact on the ant’s behavior (the probability that this edge is taken by the ant increases). The results show that the humans performing one tour through the graphs have a significant impact on the shortest path found by the MMAS. Consequently, our experiment demonstrates that in our case human intelligence can positively influence machine intelligence. To the best of our knowledge this is the first study of this kind and it is a wonderful experimental platform for explainable AI.
[1] Holzinger, A. et al. (2018). Interactive machine learning: experimental evidence for the human in the algorithmic loop. Springer/Nature: Applied Intelligence, doi:10.1007/s10489-018-1361-5.
Read the full article here:
https://link.springer.com/article/10.1007/s10489-018-1361-5

The group around Tom GRIFFITHS *) from the Cognitive Science Lab at Berkeley recently asked in their paper by Rachit Dubey, Pulkit Agrawal, Deepak Pathak, Thomas L. Griffiths & Alexei A. Efros 2018. Investigating Human Priors for Playing Video Games. arXiv:1802.10217: “What makes humans so good at solving seemingly complex video games?”.
(Spoiler short answer in advance: we don’t know – but we can gradually improve our understanding on this topic).
The authors did cool work on investigating the role of human priors for solving video games. On the basis of a specific game, they conducted a series of ablation-studies to quantify the importance of various priors on human performance. For this purpose they modifyied the video game environment to systematically mask different types of visual information that could be used by humans as prior data. The authors found that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Their results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play.
Read the original paper here:
https://arxiv.org/abs/1802.10217
Or at least glance it over via the ArxiV sanity preserver by Andrew KARPATHY:
https://www.arxiv-sanity.com/search?q=+Investigating+Human+Priors+for+Playing+Video+Games
Videos and the game manipulations are available here:
https://rach0012.github.io/humanRL_website
*) Tom Griffiths is Professor of Psychology and Cognitive Science and is interested in developing mathematical models of higher level cognition, and understanding the formal principles that underlie human ability to solve the computational problems we face in everyday life. His current focus is on inductive problems, such as probabilistic reasoning, learning causal relationships, acquiring and using language, and inferring the structure of categories. He tries to analyze these aspects of human cognition by comparing human behavior to optimal or “rational” solutions to the underlying computational problems. For inductive problems, this usually means exploring how ideas from artificial intelligence, machine learning, and statistics (particularly Bayesian statistics) connect to human cognition.
See the homepage of Tom here:
Enjoy the new version of our travelling snakesman game:
https://human-centered.ai/gamification-interactive-machine-learning/
Please follow the instructions given. By playing this game you help to proof the following hypothesis:
“A human-in-the-loop enhances the performance of an automatic algorithm”

Human-in-the-Loop-AI
This is really very interesting. In the recent April, 5, 2018, TWiML & AI (This Week in Machine Learning and Artificial Intelligence) podcast, Robert MUNRO (a graduate from Stanford University, who is an recognized expert in combining human and machine intelligence) reports on the newly branded Figure Eight [1] company, formerly known as CrowdFlower. Their Human-in-the-Loop AI platform supports data science & machine learning teams working on various topics, including autonomous vehicles, consumer product identification, natural language processing, search relevance, intelligent chatbots, and more. Most recently on disaster response and epidemiology. This is a further proof on the enormous importance and potential usefulness of the human-in-the-loop interactive machine Leanring (iML) approach! Listen to this awesome discussion led excellently by Sam CHARRINGTON:
https://twimlai.com/twiml-talk-125-human-loop-ai-emergency-response-robert-munro/
This discussion fits well to the previous discussion with Jeff DEAN (head of the Google Brain team) – who emphasized the importance of health and the limits of automatic approaches including deep learning. Enjoy to listen directly at:
https://twimlai.com/twiml-talk-124-systems-software-machine-learning-scale-jeff-dean/
[1] https://www.figure-eight.com/resources/human-in-the-loop

Our strategic aim is to find solutions for data intensive problems by the combination of two areas, which bring ideal pre-conditions towards understanding intelligence and to bring business value in AI: Human-Computer Interaction (HCI) and Knowledge Discovery (KDD). HCI deals with questions of human intelligence, whereas KDD deals with questions of artificial intelligence, in particular with the development of scalable algorithms for finding previously unknown relationships in data, thus centers on automatic computational methods. A proverb attributed perhaps incorrectly to Albert Einstein illustrates this perfectly: “Computers are incredibly fast, accurate, but stupid. Humans are incredibly slow, inaccurate, but brilliant. Together they may be powerful beyond imagination” [1].
An article published on February, 18, 2018 by David Shaywitz [2] from Forbes reports on the recent purchase of the oncolology data company Flatiron Health for the enormous sum of 2,1 Billion USD (remember: Deep Mind was purchased by Google for a mere 400 million GBP 😉
This supports a few hypotheses which I try to convince my students all the time (but they won’t believe me unless Google is doing it 😉
a) those who can turn raw health data into insights and understandable knowledge can produce value
b) data – and particularly big data – is useless for the decision maker, what they need is reliable, valuable and trustworthy information
c) for the complexity of sensemaking from health data we (still) need a human-in-the-loop: Humans (still) exceed machine performance in understanding the context and explaining the underlying explanatory factors of the data
d) consequently this is a good example for the business value of our HCI-KDD approach: Let the computer find in arbitrarily high-dimensional spaces what no human is able to do – but let the human do what no computer is able to do: BOTH working together are powerful beyond imagination!
Flatiron Health [3] is a company which is specialized on health data curation, supported by technology of course, but mostly done manually by human experts in the Mechanical Turk style. Remark: The name mechanical turk has historic origins as it was inspired by an automatic 18th-century chess-playing machine by Wolfgang von Kempelen, that beats e.g. Benjamin Franklin in chess playing – and was acclaimed as “AI”. However, ti was later revealed that it was neither a machine nor an automatic device – in fact it was a human chess master hidden in a secret space under the chessboard and controlling the movements of an humanoid dummy. Similarly, services which help to solve problems via human intelligence are called “Mechanical Turk online services”.
[1] Holzinger, A. 2013. Human–Computer Interaction and Knowledge Discovery (HCI-KDD): What is the benefit of bringing those two fields to work together? In: Cuzzocrea, Alfredo, Kittl, Christian, Simos, Dimitris E., Weippl, Edgar & Xu, Lida (eds.) Multidisciplinary Research and Practice for Information Systems, Springer Lecture Notes in Computer Science LNCS 8127. Heidelberg, Berlin, New York: Springer, pp. 319-328, doi:10.1007/978-3-642-40511-2_22
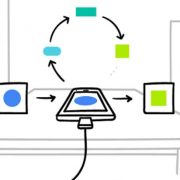
The Google Research Group [1] is always doing awesome stuff, the most recent one is on Federated Learning [2], which enables e.g. smart phones (of course any computational device, and maybe later all internet-of-things, intelligent sensors in either smart hospitals or in smart factories etc.) to collaboratively learn a shared representation model, whilst keeping all the training data on the local devices, decoupling the ability to do machine learning from the need to store the data centralized in the cloud. This goes beyond the use of local models that make predictions on mobile devices (like the Mobile Vision API and On-Device Smart Reply) by bringing model training to the device as well – which is great. The problem with standard approaches is that you always need centralized training data – either on your USB-stick, as the medical doctors do, or in a sophisticated centralized data center.
The basic idea is that the mobile device downloads the current modela and subsequently improves it by learning from data on the respective device, and then summarizes the changes as a small focused update. The remarkable detail is that only this update to the model is sent to the cloud (yes, here privacy, data protection safety and security is challenged see e.g. [3] – but this is much easier to do with this small data – as when you would do it with the raw data – think for example on patient data), where it is immediately averaged with other devicer updates to improve the shared model. All the training data remains on the local devices, and no individual updates are stored in the cloud.
The Google Group recently solved a lot of algorithmic and technical challenges. In a typical machine learning system, an optimization algorithm e.g. Stochastic Gradient Descent (SGD) [4] runs on a large dataset partitioned homogeneously across servers in the cloud. Such highly iterative algorithms require low-latency, high-throughput connections to the training data. But in the Federated Learning setting, the data is distributed across millions of devices in a highly uneven fashion. In addition, these devices have significantly higher-latency, lower-throughput connections and are only intermittently available for training.
This calls for a lot of further investigations with interactive Machine Learning (iML) bringing the human-into-the loop, i.e. making use of human cognitive abilities. This can be of particular interest to solve problems, where learning algorithms suffer due to insufficient training samples (rare events, single events), where we deal with complex data and/or computationally hard problems. For example, “doctors-in-the-loop” can help with their long-term experience and heursitic knowledge to solve problems which otherwise would remain NP-hard [5, 6]. A further step is with many humans-in-the-loop: Such collaborative interactive Machine Learning (ciML) can help in many application areas and domains, e.g. in in health informatics (smart hospital) or in industrial applications (smart factory) [7].
Read the original article, posted on April, 6, 2017, here:
https://research.googleblog.com/2017/04/federated-learning-collaborative.html
[1] https://research.googleblog.com
[2] NIPS Workshop on Private Multi-Party Machine Learning, Barcelona, December, 9, 2016, https://pmpml.github.io/PMPML16/
[3] Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., Mcmahan, H. B., Patel, S., Ramage, D., Segal, A. & Seth, K. 2016. Practical Secure Aggregation for Federated Learning on User-Held Data. arXiv preprint arXiv:1611.04482.
[4] Bottou, L. 2010. Large-scale machine learning with stochastic gradient descent. Proceedings of COMPSTAT’2010. Springer, pp. 177-186. doi:10.1007/978-3-7908-2604-3_16 (N.B.: 836 citations as of 08.04.2017)
[5] Holzinger, A. 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Brain Informatics, 3, (2), 119-131, doi:10.1007/s40708-016-0042-6
[6] Holzinger, A., Plass, M., Holzinger, K., Crisan, G., Pintea, C. & Palade, V. 2016. Towards interactive Machine Learning (iML): Applying Ant Colony Algorithms to solve the Traveling Salesman Problem with the Human-in-the-Loop approach. In: Springer Lecture Notes in Computer Science LNCS 9817. Heidelberg, Berlin, New York: Springer, pp. 81-95, [pdf]
[7] Robert, S., Büttner, S., Röcker, C. & Holzinger, A. 2016. Reasoning Under Uncertainty: Towards Collaborative Interactive Machine Learning. In: Machine Learning for Health Informatics: Lecture Notes in Artifical Intelligence LNAI 9605. Springer, pp. 357-376, [pdf]
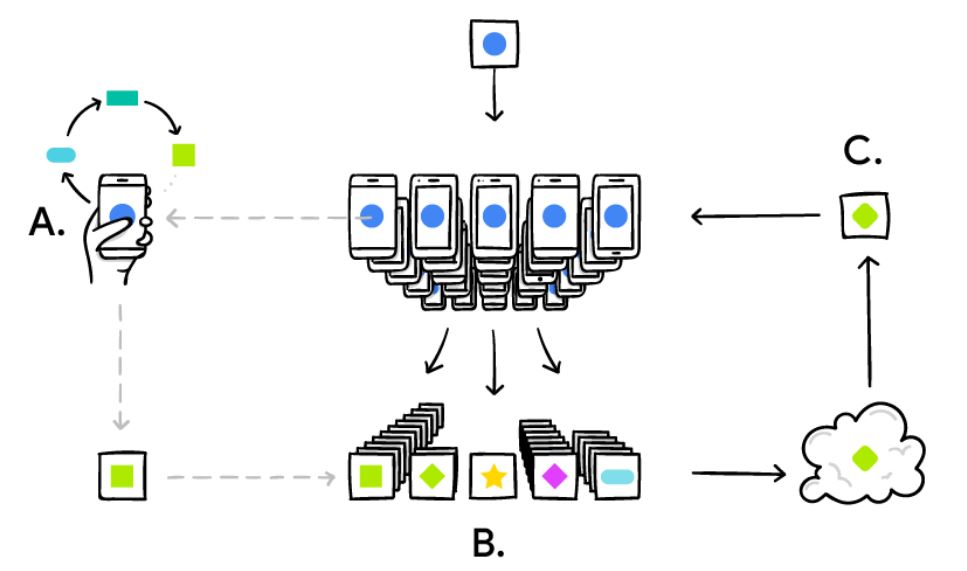 Image source: https://research.googleblog.com/2017/04/federated-learning-collaborative.html
Image source: https://research.googleblog.com/2017/04/federated-learning-collaborative.html