



Raphaël MARÉE from the Montefiori Institute, Unviersity of Liege will visit us in week 51 and give a lecture on
Open and Collaborative Digital Pathology using Cytomine
When: Thursday, 20th December, 2018, at 10:00
Where: BBMRI Conference Room (joint invitation of BBMRI, ADOPT and HCI-KDD)
Address: Neue Stiftingtalstrasse 2/B/6, A-8010 Graz, Austria
Abstract:
In this talk Raphael Maree will present the past, present, and future of Cytomine.
Cytomine [1], [2] is an open-source software, continuously developed since 2010. It is based on modern web and distributed software development methodologies and machine learning, i.e. deep learning. It provides remote and collaborative features so that users can readily and securely share their large-scale imaging data worldwide. It relies on data models that allow to easily organize and semantically annotate imaging datasets in a standardized way (e.g. to build pathology atlases for training courses or ground-truth datasets for machine learning). It efficiently supports digital slides produced by most scanner vendors. It provides mechanisms to proofread and share image quantifications produced by machine/deep learning-based algorithms. Cytomine can be used free of charge and it is distributed under a permissive license. It has been installed at various institutes worldwide and it is used by thousands of users in research and educational settings.
Recent research and developments will be presented such as our new web user interfaces and new modules for multimodal and multispectral data (Proteomics Clin Appl, 2019), object recognition in histology and cytology using deep transfer learning (CVMI 2018), user behavior analytics in educational settings (ECDP 2018), as well as our new reproducible architecture to benchmark bioimage analysis workflows.
Short Bio:
Raphaël Marée received the PhD degree in computer science in 2005 from the University of Liège, Belgium, where he is now working at the Montefiore EE&CS Institute (https://www.montefiore.ulg.ac.be/~maree/). In 2010 he initiated the CYTOMINE research project (https://uliege.cytomine.org/), and since 2017 he is also co-founder of the not-for-profit Cytomine cooperative (https://cytomine.coop). His research interests are in the broad area of machine learning, computer vision techniques, and web-based software development, with specific focus on their applications on big imaging data such as in digital pathology and life science research, while following open science principles.
[1] Raphaël Marée, Loïc Rollus, Benjamin Stévens, Renaud Hoyoux, Gilles Louppe, Rémy Vandaele, Jean-Michel Begon, Philipp Kainz, Pierre Geurts & Louis Wehenkel 2016. Collaborative analysis of multi-gigapixel imaging data using Cytomine. Bioinformatics, 32, (9), 1395-1401, doi:10.1093/bioinformatics/btw013.
Google Scholar Profile of Raphael Maree:
https://scholar.google.com/citations?user=qG66mF8AAAAJ&hl=en
Homepage of Raphael Maree:
https://www.montefiore.ulg.ac.be/~maree/


An awesome question stated in an article by Michael BEREKET and Thao NGUYEN (Febuary 7, 2018) brings it straight to the point: Deep learning has revolutionized the field of computer vision. So why are pathologists still spending their time looking at cells through microscopes?
The most famous machine learning experiments have been done with recognizing cats (see the video by Peter Norvig) – and the question is relevant, how different are these cats from the cells in histopathology?
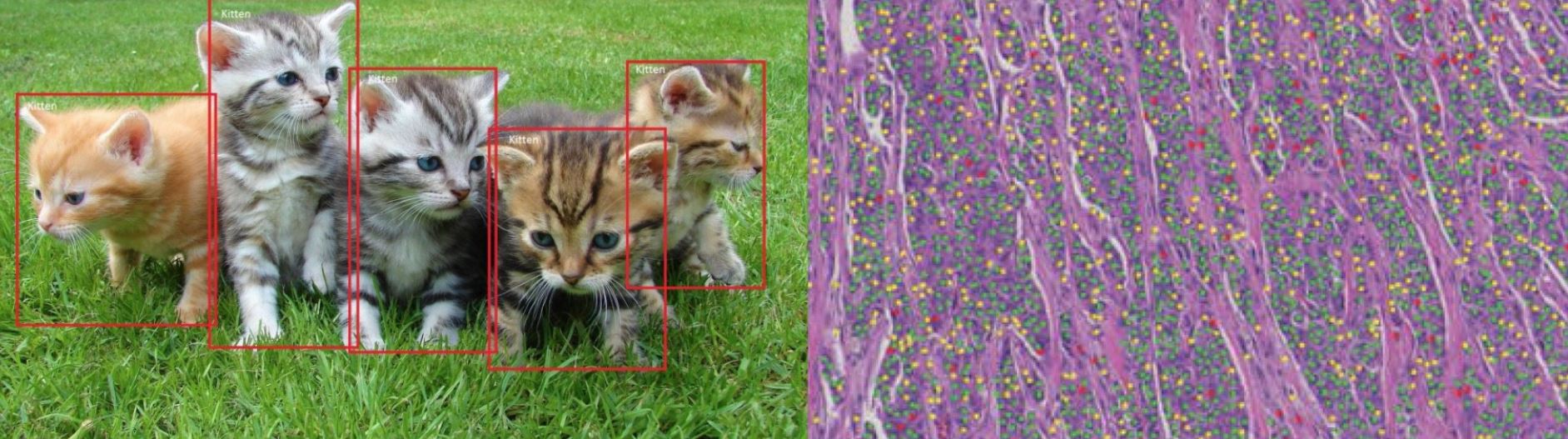
Machine Learning, and in particular deep learning, has reached a human-level in certain tasks, particularly in image classification. Interestingly, in the field of pathology these methods are not so ubiqutiously used currently. A valid question indeed is: Why do human pathologists spend so much time with visual inspection? Of course we restrict this debate on routine tasks!
This excellent article is worthwhile giving a read:
Stanford AI for healthcare: How different are cats from cells
Source of the animated gif above:
https://giphy.com/gifs/microscope-fluorescence-mitosis-2G5llPaffwvio

Yoshua BENGIO from the Canadian Institute for Advanced Research (CIFAR) emphasized during his workshop talk “towards disentangling underlying explanatory factors” (cool title) at the ICML 2018 in Stockholm, that the key for success in AI/machine learning is to understand the explanatory/causal factors and mechanisms. This means generalizing beyond identical independent data (i.i.d.) – and this is crucial for our domain in medcial AI, because current machine learning theories and models are strongly dependent on this iid assumption, but applications in the real-world (we see this in the medical domain every day!) often require learning and generalizing in areas simply not seen during the training epoch. Humans interestingly are able to protect themselves in such situations, even in situations which they have never seen before. Here a longer talk (1:17:04) at Microsoft Research Redmond on January, 22, 2018 – awesome – enjoy the talk, I recommend it cordially to all of my students!

We just had our keynote by Randy GOEBEL from the Alberta Machine Intelligence Institute (Amii), working on enhnancing understanding and innovation in artificial intelligence:
https://cd-make.net/keynote-speaker-randy-goebel
You can see his slides with friendly permission of Randy here (pdf, 2,680 kB):
https://human-centered.ai/wordpress/wp-content/uploads/2018/08/Goebel.XAI_.CD-MAKE.Aug30.2018.pdf
Here you can read a preprint of our joint paper of our explainable ai session (pdf, 835 kB):
GOEBEL et al (2018) Explainable-AI-the-new-42
Randy Goebel, Ajay Chander, Katharina Holzinger, Freddy Lecue, Zeynep Akata, Simone Stumpf, Peter Kieseberg & Andreas Holzinger. Explainable AI: the new 42? Springer Lecture Notes in Computer Science LNCS 11015, 2018 Cham. Springer, 295-303, doi:10.1007/978-3-319-99740-7_21.
Here is the link to our session homepage:
https://cd-make.net/special-sessions/make-explainable-ai/
amii is part of the Pan-Canadian AI Strategy, and conducts leading-edge research to push the bounds of academic knowledge, and forging business collaborations both locally and internationally to create innovative, adaptive solutions to the toughest problems facing Alberta and the world in Artificial Intelligence/Machine Learning.
Here some snapshots:


R.G. (Randy) Goebel is Professor of Computing Science at the University of Alberta, in Edmonton, Alberta, Canada, and concurrently holds the positions of Associate Vice President Research, and Associate Vice President Academic. He is also co-founder and principle investigator in the Alberta Innovates Centre for Machine Learning. He holds B.Sc., M.Sc. and Ph.D. degrees in computer science from the University of Regina, Alberta, and British Columbia, and has held faculty appointments at the University of Waterloo, University of Tokyo, Multimedia University (Malaysia), Hokkaido University, and has worked at a variety of research institutes around the world, including DFKI (Germany), NICTA (Australia), and NII (Tokyo), was most recently Chief Scientist at Alberta Innovates Technology Futures. His research interests include applications of machine learning to systems biology, visualization, and web mining, as well as work on natural language processing, web semantics, and belief revision. He has experience working on industrial research projects in scheduling, optimization, and natural language technology applications.
Here is Randy’s homepage at the University of Alberta:
https://www.ualberta.ca/science/about-us/contact-us/faculty-directory/randy-goebel
The University of Alberta at Edmonton hosts approximately 39k students from all around the world and is among the five top universities in Canada and togehter with Toronto and Montreal THE center in Artificial Intelligence and Machine Learning.

The IEEE DISA 2018 World Symposium on Digital Intelligence for Systems and Machines was organized by the TU Kosice:
Here you can download my keynote presentation (see title and abstract below)
a) 4 Slides per page (pdf, 5,280 kB):
HOLZINGER-Kosice-ex-AI-DISA-2018-30Minutes-4×4
b) 1 slide per page (pdf, 8,198 kB):
HOLZINGER-Kosice-ex-AI-DISA-2018-30Minutes
c) and here the link to the paper (IEEE Xplore)
From Machine Learning to Explainable AI
d) and here the link to the video recording
https://archive.tp.cvtisr.sk/archive.php?tag=disa2018##videoplayer
Title: Explainable AI: Augmenting Human Intelligence with Artificial Intelligence and v.v
Abstract: Explainable AI is not a new field. Rather, the problem of explainability is as old as AI itself. While rule‐based approaches of early AI are comprehensible “glass‐box” approaches at least in narrow domains, their weakness was in dealing with uncertainties of the real world. The introduction of probabilistic learning methods has made AI increasingly successful. Meanwhile deep learning approaches even exceed human performance in particular tasks. However, such approaches are becoming increasingly opaque, and even if we understand the underlying mathematical principles of such models they lack still explicit declarative knowledge. For example, words are mapped to high‐dimensional vectors, making them unintelligible to humans. What we need in the future are context‐adaptive procedures, i.e. systems that construct contextual explanatory models for classes of real‐world phenomena.
Maybe one step is in linking probabilistic learning methods with large knowledge representations (ontologies), thus allowing to understand how a machine decision has been reached, making results re‐traceable, explainable and comprehensible on demand ‐ the goal of explainable AI.


The group around Tom GRIFFITHS *) from the Cognitive Science Lab at Berkeley recently asked in their paper by Rachit Dubey, Pulkit Agrawal, Deepak Pathak, Thomas L. Griffiths & Alexei A. Efros 2018. Investigating Human Priors for Playing Video Games. arXiv:1802.10217: “What makes humans so good at solving seemingly complex video games?”.
(Spoiler short answer in advance: we don’t know – but we can gradually improve our understanding on this topic).
The authors did cool work on investigating the role of human priors for solving video games. On the basis of a specific game, they conducted a series of ablation-studies to quantify the importance of various priors on human performance. For this purpose they modifyied the video game environment to systematically mask different types of visual information that could be used by humans as prior data. The authors found that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Their results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play.
Read the original paper here:
https://arxiv.org/abs/1802.10217
Or at least glance it over via the ArxiV sanity preserver by Andrew KARPATHY:
https://www.arxiv-sanity.com/search?q=+Investigating+Human+Priors+for+Playing+Video+Games
Videos and the game manipulations are available here:
https://rach0012.github.io/humanRL_website
*) Tom Griffiths is Professor of Psychology and Cognitive Science and is interested in developing mathematical models of higher level cognition, and understanding the formal principles that underlie human ability to solve the computational problems we face in everyday life. His current focus is on inductive problems, such as probabilistic reasoning, learning causal relationships, acquiring and using language, and inferring the structure of categories. He tries to analyze these aspects of human cognition by comparing human behavior to optimal or “rational” solutions to the underlying computational problems. For inductive problems, this usually means exploring how ideas from artificial intelligence, machine learning, and statistics (particularly Bayesian statistics) connect to human cognition.
See the homepage of Tom here:

Microsoft invests into explainable AI and acquired on June, 20, 2018 Bonsai, a California start-up, which was founded by Mark HAMMOND and Keen BROWNE in 2014. Watch an excellent introduction “Programming your way to explainable AI” by Mark HAMMOND here:
and read read the original story about the acquisition here:
“No one really knows how the most advanced algorithms do what they do. That could be a problem.” Will KNIGHT in “The dark secret of the heart of AI”
https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai
A very nice and interesting article by Rudina SESERI in the recent TechCrunch blog (read the orginal blog entry below): at first Rudina points out that the main problem is in data; and yes, indeed, data should always be the first consideration. We consider it a big problem that successful ML approaches (e.g. the mentioned deep learning, our PhD students can tell you a thing or two about it 😉 greatly benefit from big data (the bigger the better) with many training sets; However, it certain domain, e.g. in the health domain we sometimes are confronted with a small number of data sets or rare events, where we suffer of insufficient training samples [1]. This calls for more research towards how we can learn from little data (zero-shot learning), similar as we humans do: Rudina does not need to show her children 10 million samples of a dog and a cat, so that her children can safely discriminate a dog from a cat. However, what I miss in this article is something different, the word trust. Can we trust our machine learning results? [2] Whilst, for sure we do not need to explain everything all the time, we need possibilities to make machine decisions transparent on demand and to check if something could be plausible. Consequently, Explainable AI can be very important to foster trust in machine learning specifically and artificial intelligence generally.
[1] https://link.springer.com/article/10.1007/s40708-016-0042-6